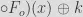The Latest News from Research at Kudelski Security
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Cryptography
November 17, 2022
Some AES CBC Encryption Myth-busting
No items found.
Kudelski Security Team
Myth-busting us. /ˈmɪθˌbʌs.tɪŋ/ : the act of saying or showing that something generally thought to be true is not, in fact, true, or is different from how it is usually described.
Cambridge Dictionary
Symmetric block ciphers such as the Advanced Encryption Standard or AES (FIPS 197) are a widespread cryptographic primitive extensively used to provide data confidentiality and authentication in countless platforms and systems.
However, a block cipher cannot be used “as is” to protect data, it must be run in a so-called mode of operation to be able to securely process messages of arbitrary length. There exist many proposed and standardized modes of operation, for instance NIST currently approves several confidentiality, authentication, and authenticated encryption modes in the SP 800-38 document suite.
SP 800-38A (currently under revision) discusses five confidentiality modes: ECB, CBC, CFB, OFB, and CTR. ECB is particularly bad, not being randomized; its use is generally discouraged. CBC, CFB, OFB, and CTR are all malleable.
The best practice to avoid malleability is, of course, to add an authentication layer to the message, for instance, with a Message Authentication Code (MAC); the choice is either to go for an authenticated encryption mode (such as GCM or CCM) or to combine a confidentiality mode with a hash-based MAC (AES-CBC with HMAC-SHA-256 is a common choice).
We can say that CBC and CTR are probably the most ubiquitous modes of operation for confidentiality; they lie as well at the core of authenticated encryption modes such as GCM and CCM.
The general preference is probably for CTR, as CBC has no real advantage over it. However, IV reuse has much more catastrophic results for CTR than for CBC. A security proof for the CBC mode of operation can be found here. Note that for CBC, the IV must be chosen randomly for each encryption (beware, a counter is not a safe choice).
So, what can we say about CBC mode of operation? What are its properties? Check out this Wikipedia page for the (in)famous penguin image. Indeed, cryptographic wisdom (or folklore?) and Wikipedia tell us two things about CBC versus other modes of operation:
CBC (like ECB) requires the underlying block cipher (e.g., AES) to be implemented in both encrypt (for CBC encryption) and decrypt (for CBC decryption) directions. CTR has no such demand because encryption and decryption are basically the same function, where the underlying block cipher is used in the encrypt direction.
CBC encryption is inherently serial and not parallelizable, while CBC decryption is. CTR does not present this issue as encryption and decryption can be fully parallelized at block level.
There are no proofs of the above statements. In fact, both are (at least partially) wrong.
Why? For our discussion here, let us stick to the case where the message to encrypt is fully known in advance (no online encryption).
In CBC encryption, the user is supposed to choose a random IV and then run the process shown in the following picture (4 full blocks of a message):
The randomness of the IV affects all ciphertext blocks via the XOR feedback, and the process looks inherently serial. The corresponding decryption operation is as follows:
One can see that the IV is useful only to recover the first plaintext correctly. Even with a wrong IV, the decryption works “almost” fine. Each plaintext block depends on only two ciphertext blocks, so the decryption process can be parallelized.
Now, so far so good, but… let’s try to “reverse” the direction of CBC encryption. What if the user randomly chooses the last ciphertext block instead of the IV? The process would then be run backward as follows:
In the end, the user will come up with a legitimate CBC encryption, and CBC decryption will work fine and give the correct plaintext. Only the process of generating the ciphertext and IV is different. Note that the IV is still “randomly chosen” in the sense that it depends on the last ciphertext block, which has been chosen randomly.
But wait! The underlying block cipher is now used in the decrypt direction for CBC encryption. Therefore, one can use the underlying block cipher (e.g. AES) in the decrypt direction to perform both CBC encryption and decryption. First myth is busted!
Small digression: In fact, since AES in either encryption or decryption is a good pseudo random permutation (PRP), one could use encryption for both and save cycles and code size (which is good for constrained devices, although this can be no more considered “standard”):
Regarding the second common belief, note that one could run encryption in the following way: instead of generating the last ciphertext block randomly, one can split the message in two and generate the middle ciphertext block randomly (C2 in the picture below). Then, he can proceed both backward as explained above for the first message section and forward as classic CBC encryption for the second message section:
This has the disadvantage of requiring both encrypt and decrypt directions for the underlying block cipher for CBC encryption, but the two processes can clearly be run in parallel. As a result, if we have two AES instances, we can have a parallelization factor of 2 for the CBC encryption. Second myth is also busted!
This modified flow for CBC encryption is secure. In fact, what is lying at the core of the security proof for the CBC mode is the bound on the attacker advantage to distinguish a CBC encryption from a garbage emitter, i.e., an oracle that spits out random data instead of the real result of encryption.
The existing proof for CBC relates this advantage to the probability of causing a collision on an input of the underlying block cipher, considered as a PRP. If the attacker succeeds in producing a collision, he wins and can distinguish the CBC encryption oracle from the garbage oracle.
The paper bounds this probability by making the key observation that the values that are XORed with the plaintext blocks to form the inputs of the PRP are always independent of them and chosen uniformly at random because they are either the IV or the result of applying the PRP on a new input. But this is also the case for the modified flow, where the last ciphertext block is chosen randomly. Therefore, we can have the exact same proof of security for the CBC encryption with the modified flow (choice of random, last ciphertext block instead of random IV).
Note that for a given message and a given block cipher key, and considering straightforward CBC encryption, each ciphertext block is fully determined by choice of the IV, and it is obvious that the relation is a bijection. In fact, one could consider the IV as the “zero” ciphertext coming from a previous (non-existing) iteration, and the consideration remains valid if one “shifts” along the chain and chooses an intermediate cipher text block: all following ciphertext blocks are fully determined, and their values are bijections of the chosen value over the block space.
This is also true considering the modified-flow CBC encryption running in the backward direction switching the direction of the block cipher. It also remains true for all ciphertext blocks whenever an intermediate ciphertext block is chosen, and the others are generated proceeding in both directions.
Therefore, in our modified flows, if one chooses one ciphertext block uniformly at random, all others, including the IV are also distributed uniformly at random (although obviously not independent); but an IV chosen uniformly at random is precisely the starting point of straightforward CBC encryption.
Conclusion
We thus conclude that the advantage of an adversary to distinguish between the original or the modified-flow CBC encryption processes should be negligible. So, don’t bother too much about crypto folklore, and enjoy parallel CBC encryption!
2022
Conferences and events
Cryptography
November 15, 2022
Practical fault attacks against SM4
No items found.
Kudelski Security Team
During the Hardwear.io 2022 conference, Nicolas and I presented hardware attacks against the SM4 block cipher. In this post, I’ll give more details about the fault attacks we presented and the tools we have released.
We started to study this algorithm when we found the CH569w SoC from WCH containing a hardware accelerator doing SM4. Then we figured out that SM4 is the de facto standard in China, and it seems to be more and more deployed. For example, ARM introduced two instructions since ARMv8.4, sm4e a sm4ekey to speed up SM4 computation. RISC-V also integrated two instructions doing similar accelerations.
According to the draft IETF, SM4 is a block cipher taking a 128-bit key and performing 32 rounds on a 128-bit plaintext block. Like AES, it is composed of a key schedule. It generates 36 round keys of 32 bits each. The first four round keys are the secret key XORed with the constants FKs called the family keys. Then, each round key is generated according to the following diagram, where the CKs are constants defined in the standard.
For the following, as a notation, all the uppercase letters describe 32-bit words and lowercase letters are bytes. During one round, only one new round key is generated, the other three are simply shifted on the right. Thus, from four consecutive round keys, the algorithm is invertible.
The last 32 round keys are used during the 32 rounds of the encryption or the decryption of a block. One round of SM4 is very similar to the key schedule. A round transformed a 128-bit state into another state with the following operations:
One of the differences with the key schedule is the T function which is slightly different than T’ of the key schedule. The function T works according to the following diagram:
Where L is a linear transformation with 32-bit input and 32-bit output. Used for diffusion among a word. S are S-Box with 8-bit input and 8-bit output. Similarly as for AES, the Sbox is based on inverse and affine transformations.
The first fault attack in the literature was published in 2006 by Zhang and Wu. The paper is written in Chinese, but the attack is a basic block for all further fault attacks, and some papers in English give a nice description of this attack. The idea of this fault attack is to introduce a random byte in the second, third, or fourth word at the input of the last round. Thus the fault is directly observable in the ciphertext since these words are simply shifted during a round. The T function input is also corrupted and its output is observable in the ciphertext. For example, a fault in the third word of the last round results in the following:
The idea of the attack is to recover a byte k of the last round key by applying differential analysis from the random byte fault 𝛼 introduced. It starts by writing the formulas of difference of the Sbox output:
All the Sbox inputs are replaced by the variable x for simplicity. Then the attack proceeds backwards until the output of T by applying the inverse of the L function:
We obtain a word with only one non-zero byte. It matches the position of the byte fault injected. Now the problem is to find an unknown byte x such that:
To solve this problem, the attack builds a static table IN such that
This table is unique for the SM4 SBox. It contains the set of x satisfying the previous equation. Building this table would give that for each entry, we would have on average only two different x. The attack proceeds as follow:
From a faulted ciphertext it computes 𝛼 and 𝛽
Looks at IN[𝛼][𝛽] and deduce a list of candidates for x.
From the x stored in the table XOR all the input bytes to recover the round key byte candidate k.
Keep the list of the round key byte candidates.
Then until the intersection of all the lists of candidates does not have a unique element repeat the previous steps.
On average, we would need only two faulted ciphertexts to recover one round key byte. Thus, we would need eight faulted ciphertexts to recover the full round key. As soon as the round key is recovered, we can invert the last round and apply the same attack on the previous round, and so on. As soon as we have recovered four round keys we can invert the key schedule and recover the secret key. On average, we would need a total of 32 different faults. The papers about SM4 fault attacks often have an experiments section to show the performances of their attacks but they never released the software to reproduce their results. However, we found an implementation of the previous fault attack, and we used it as a starting point.
This attack has the advantage to be practical since the faulted ciphertext only differed from the correct ciphertext by only five bytes. For example, we have simulated faults at the last round and if we XOR them with the correct ciphertext (the first value in the previous list) we have the following patterns:
It is really convenient to sort the fault in a huge list of random looking ciphertexts. We have implemented this attack in a tool called phoenixSM4 which is integrated in the great repository of the side channel marvels. This tool can be easily installed as a Python package:
pip install phoenixSM4
Applying this attack on the previous faults would allow to recover the last round key byte per byte.
Then we tried to applied this attack on a more interesting case. We used a tool we developed called Glitchoz0r 3000 presented during R2Con 2020 to inject faults in a ARM binary using a C implementation of SM4. We emulate a fault skipping an instruction and we collected all the resulting faulted ciphertexts.
But then we sorted our fault to find the same pattern we were not able to find it. Nevertheless we had other interesting patterns:
But we could not apply the fault attack directly. We looked back at the academic literature and we figure out an extended fault attacks publish in 2007 by Li and Gu. The main idea of the attack is to inject the same fault but one round earlier. In this scenario, the fault would propagate to the full word at the next round and impacts all the bytes of the SBox inputs.
Since the inputs and the last round output are still available, we can apply the previous attack but this time in parallel on all the round key bytes. One word is still not impacted by the fault and it allows to still filter the faulted ciphertexts according to this pattern. In fact, the paper is going even further by analyzing faults happening even one round earlier, and in this case, only two faults allows to recover two full round keys in a row.
We implemented this attack as well and we found out that it is possible to combine this attack with the previous one by keeping the key byte candidate between each fault. It allows to exploit fault happening at the three last rounds. As soon as a round key is recovered, our tool will revert the round and continue the attack until four round keys are recovered. We also noticed that the extended attack does not apply to the second round since the output is not directly observable. For some fault happening in hardware, the computation of T was faulted directly but not the input register value. Consequently, for this kind of faults, the attack is still applicable and it extends the applicability of the fault attacks to this word as well.
Thus we tried our tool on the previous faults we collected before:
We can see that a round key is fully recovered for some steps and not byte per byte like previously. Then from the four round keys, it is possible to get back to the secret key with the inverse key schedule we implemented in Stark:
We tested our tool on the faults generated on the real hardware. We used EM fault injection with NewAE’s ChipShouter using pulse of 400V and 150ns duration and the stock clockwise coil.
After a scan of several days we obtain some interesting faulted ciphertexts for a plaintext set to “A” sixteen times. We used our tool on them:
This demonstrates that the SM4 implementation of this SoC is vulnerable to low-cost fault injection. Our tool is published as open-source, and we encourage you to test it and even correct or improve it.
2022
Crypto
Cryptography
Data privacy
Defense
Device security
November 10, 2022
Introducing Shufflecake: plausible deniability for multiple hidden filesystems on Linux
No items found.
Kudelski Security Team
Today we are excited to release Shufflecake, a tool aimed at helping people whose freedom of expression is threatened by repressive authorities or dangerous criminal organizations, in particular: whistleblowers, investigative journalists, and activists for human rights in oppressive regimes. Shufflecake is FLOSS (Free/Libre, Open Source Software). Source code in C is available and released under the GNU General Public License v3.0 or superior.
Shufflecake is originally based on the EPFL M.Sc. Thesis “Hidden Filesystems Design and Improvement” by our former student Elia Anzuoni (under supervision of Dr. Tommaso Gagliardoni and Prof. Edouard Bugnion) during his internship on the Kudelski Security Research Team.
Introduction
Shufflecake is a tool for Linux that allows creation of multiple hidden volumes on a storage device in such a way that it is very difficult, even under forensic inspection, to prove the existence of such volumes. Each volume is encrypted with a different secret key, scrambled across the empty space of an underlying existing storage medium, and indistinguishable from random noise when not decrypted. Even if the presence of the Shufflecake software itself cannot be hidden – and hence the presence of secret volumes is suspected – the number of volumes is also hidden. This allows a user to create a hierarchy of plausible deniability, where “most hidden” secret volumes are buried under “less hidden” decoy volumes, whose passwords can be surrendered under pressure. In other words, a user can plausibly “lie” to a coercive adversary about the existence of hidden data, by providing a password that unlocks “decoy” data. Every volume can be managed independently as a virtual block device, i.e. partitioned, formatted with any filesystem of choice, and mounted and dismounted like a normal disc. The whole system is very fast, with only a minor slowdown in I/O throughput compared to a bare LUKS-encrypted disk, and with negligible waste of memory and disc space.
You can consider Shufflecake a “spiritual successor” of tools such as Truecrypt and Veracrypt, but vastly improved. First of all, it works natively on Linux, it supports any filesystem of choice, and can manage up to 15 nested volumes per device, so to make deniability of the existence of these partitions really plausible.
Operation
Shufflecake is made of two components: dm-sflc, which is a kernel module implementing the Shufflecake scheme as a device-mapper target for the Linux kernel, and shufflecake-userland, which is a command-line tool allowing the user to create and manage hidden volumes. The kernel module must be loaded before using the userland tool. For now the support is limited to Debian/Ubuntu and similar derivatives, testing has been done with the Linux kernel 5.13.
In a nutshell, Shufflecake allocates space for each volume as encrypted slices at random positions of the underlying device. Slices are allocated dynamically, as soon as the kernel module decides that more space than the currently used quota is required, and are interleaved to make forensic analysis more difficult. Data about the position of used and unused slices is stored in a volume-specific “position map”, which is indexed within an encrypted header at the beginning of the device. Both position map and header are indistinguishable from random data without the correct decryption key, and every slot in the header (currently up to 15 volumes) has a field containing the decryption key for the previous (i.e., “less hidden”) header and volume, thereby recursively linking all volumes and allowing the user to open all of them with a single password. This also makes overcommitment possible, i.e., if you have a 1 GiB device and you create 3 Shufflecake volumes on it, by default you will see each of these 3 volumes being 1 GiB in size (although you will start receiving I/O errors if you try to write more than 1 GiB total across all 3), which is also crucial for plausible deniability, because an adversary can never tell for sure how many other volumes are there. Notice, in fact, that if some volumes are left unopened they are not considered for the total space allocation.
A user must first init a device, for example, a physical disc, or a partition therein, or a virtual block device such as a file-backed loop device. This will first overwrite the disc with random data and then create an encrypted header section at the beginning of the device. The header contains metadata and allocation tables for 15 Shufflecake volumes. The user is asked to provide N different passwords (where N is between 1 and 15). Then, the first N sections of the header will be encrypted with each of the N passwords, while the others will be left random. The order of the given passwords is important, because it establishes a hierarchy from “less hidden” to “more hidden” volumes. Notice that it is impossible to know how many volumes there are without decrypting.
Then the user can open the volumes inside a given Shufflecake-initialised device. This is done by providing only one of the N given passwords, which unlocks one of the 15 slots in the header, and hence a device area allocated for the corresponding volume. Furthermore, the unlocked slot contains a key that allows to decrypt the previous (i.e. “less hidden”) slot in the hierarchy, thereby allowing to open all the less sensitive volumes recursively. All these volumes appear as virtual block devices under /dev/mapper and can be mounted, formatted, and used to store data.
Finally, a user can close a device and all the supported volumes therein with a single command.
Shufflecake is efficient: I/O slowdown is roughly 2x compared to a “normal” LUKS encrypted volume, which is still barely noticeable for daily desktop use, and wastes less than 1% of the available disc space. Compare this to state-of-the-art plausible deniability solutions based on WORAM techniques, with slowdowns that range from 200x to 5x with 75% of disc space wasted. A decent amount of memory (roughly 60 MiB per open volume) is required to manage the position maps in-RAM for better efficiency. There is certainly room for improvement, we didn’t focus too much on optimization for the first release, performance will surely get better in future versions.
Future Directions
We believe that Shufflecake fills a gap in the availability of robust plausible deniability solutions for Linux. The current release is still a non-production-ready prototype, so we advise against using it for really sensitive operations. However, we believe that future work will sensibly improve both security and performance, hopefully offering a really useful tool to people who live in constant danger of being interrogated with coercive methods to reveal sensitive information.
2022
Cryptography
September 19, 2022
Introducing ABE Squared: A Framework for Comparing the Efficiency of ABE Schemes
No items found.
Kudelski Security Team
Authors: Antonio de la Piedra (Kudelski Security Research Team), Marloes Venema (Radboud University Nijmegen), Greg Alpar (Radboud University Nijmegen and Open University of the Netherlands).
Attribute-based encryption (ABE) is an elegant type of public-key cryptography where secret keys are associated to attributes. It can be used for fine-grained access control on sensitive data, and the Cloud is a perfect use case.
In the past, we have shown how Attributed-based encryption schemes can be attacked. This time, we asked ourselves the following question: Given the myriad of published ABE schemes, can we accurately measure their efficiency in order to know which one is the best? And if yes, what is the best way of achieving this, and what do we mean by the best?
In order to answer this question, we have created ABE Squared, a framework for comparing the efficiency of ABE schemes and to optimize them according to the design goal, taking into account different optimization layers.
We are presenting ABE Squared this week at CHES 2022.
Attribute-based Encryption
An ABE scheme generally consists of 4 algorithms: Setup, Key generation, Encryption and Decryption. In a typical ABE deployment, a party, e.g. Alice, wants to protect her sensitive data according to a particular access policy based on attributes e.g. doctor OR nurse. In order to do that, Alice will request to a Key Generation Authority (KGA) the master public key (MPK) of the system, and she will encrypt her data accordingly.
Only parties having secret keys related to the attributes doctor, nurse can satisfy the access policy established by Alice and decrypt. In our example, Bob receives to secret keys related to the attributes doctor and Johns Hopkins Hospital, which satisfy (in this case, doctor) the access policy established by Alice.
Nowadays, mature ABE schemes mainly rely on pairing-based cryptography and are challenging to implement. Many of these implementations of ABE schemes rely on rapid prototyping frameworks such as CHARM and oftentimes only some parts of the scheme are optimized. This can be problematic, since implementing an ABE scheme requires addressing many variables such as the implementation of access policy, the group arithmetic and the type conversion. All these areas depend on the type ABE application we are designing. To aid the design process of an ABE application, improve the benchmarking capabilities of designers of ABE schemes and to provide heuristics capable of obtaining optimized versions of ABE schemes given design goal, we have created ABE Squared.
ABE Squared
ABE Squared takes into account all the layers of optimization. As inputs, it receives the theoretical description of the scheme and produces the description of the scheme that directly yields the most efficient implementation.
In this process, we choose the design goal, which is of utmost importance. For instance, some applications may require an optimized key generation variant, such as the implementation of a KGA. In order to achieve this, every layer needs to be optimized, and we create optimization approaches based on these design goals:
We first analyze the arithmetic and group operations used in the schemes by benchmarking their efficiency in the paring-friendly groups that can be used.
We show how the order of computations can be optimized, given the efficiency of the available algorithms for arithmetic in the chosen pairing-friendly group.
We show how the schemes can be instantiated in these group so to obtain the best possible efficiency, given a particular design goal. To this end, we provide new manual and heuristic techniques to convert the scheme from type 1 to type 3 and obtain the following variants of the scheme: optimized encryption (OE), optimized key generation (OK), optimized decryption (OD) and balanced approaches such as key generation/encryption and encryption/decryption.
The design goal matters
In order to show how important is to have a design goal when implementing an ABE scheme, we have taken the Wat11-I scheme and implemented using the BLS-12-381 pairing-friendly curve.
We have used all of our heuristics to obtain the OD, OE and OK variants of the same scheme:
If we compare an optimized key generation variant with a variant that has been optimized to encryption or decryption, we see that the latter requires 143 % more cycles that the former.
If we compare an optimized encryption variant with a variant that has been optimized for key generation, we see that the latter requires 153.3 % more cycles than the former.
Finally, if we compare an optimized decryption variant with an implementation optimized for key generation we see that the latter requires around 8 % more cycles. In this case, the percentage is small, because in ABE, the decryption algorithm involves mainly pairings operations and less group operations.
Comparing ABE schemes using ABE Squared
Another question we can ask is: What scheme is the best for which operation (e.g. key generation, encryption, decryption) and using which pairing-friendly curve? To illustrate how ABE Squared works, we have chosen 3 ABE schemes that share the same practical properties and structure: AC17-LU, Wat11-IV and RW13.
We see that, in general, the BLS-12-381 pairing-friendly curve provides the best performance. Moreover, the AC17-LU is the best scheme for performing encryption and decryption, whereas the RW13 scheme is the best scheme for key generation.
We started this article by asking ourselves what could be the best way of measuring the efficiency of ABE schemes. We have seen that only by first optimizing the schemes to the same design goal we can compare them in a fair manner. If you want to know more about our optimization heuristics and ABE Squared in general, you can read our paper in the IACR ePrint service.
2022
Zero-Knowledge
July 7, 2022
Implementing ZK-focused hash schemes
No items found.
Kudelski Security Team
In my last post, I described the ZK-oriented Ciminion AE (Dobraunig et al., 2021) scheme and implemented it using the circom2 DSL for writing zkSNARK circuits.
In this second part I present an overview of the different hashing constructions that have been proposed in the last few years, starting from MiMC (Albrecht et al., 2016) and finishing with Griffin (Grassi et al., 2022). This allows us to visit another DSL for writing SNARKs (Leo) and to explore embedded DSLs. These libraries provide APIs for constraint definition, compilation and proof generation from languages such as Go and Rust. Two examples are gnark and arkworks. Finally, I include a small list of ingredients that can be used to build a checklist when auditing circuits.
Hashing in zkSNARK circuits
In the first part of this series of articles, we dealt with encryption schemes designed for zkSNARKs applications. For instance, they can be used to prove that a certain piece of sensitive data has been encrypted using a particular key (think about cloud storage) or that a ciphertext has been correctly encrypted using a particular encryption scheme.
In general, using hashes in circuits means that a prover can convince a verifier that she knows the preimage of a value x given the hash of x (i.e. H(X)). In particular, this fact can serve to prove the knowledge of a secret, the membership of a sensitive value in a set, to obtain nullifiers and commitments, and more commonly, to implement set membership proofs in Merkle tree accumulators. In all these cases the performance of the hash scheme utilized is of utmost importance and schemes such as SHA-256 don’t provide the same performance in a circuit in comparison to a scheme based on a reduced number of multiplication and addition gates.
Structure of ZK-focused hash schemes
Typically, hashing schemes that target ZK circuits rely on the same type of linear and non-linear layers (we should note that in this article we mainly focus and describe schemes which partially or mainly optimize and measure the performance and size of their schemes using Rank-1 quadratic constraints as metric. We left schemes such as Reinforced Concrete (Grassi et al., 2021), focused on PLONK and others based on Elliptic Curve operations for another time). R1CS constraints describe a circuit via polynomials, where circuit multiplication and addition gates act over the prime Field Fp of a pairing-friendly elliptic curve. Since the proof generation complexity is generally related to the number of constraints (mainly multiplication gates, we can say additions are free), the aim of scheme designers is to reduce the number of multiplications.
In these schemes, in the linear layer, we cannot manipulate individual bits as we generally do in common block ciphers and hash functions, and matrix multiplication is used instead, via maximum distance separable (MDS) matrices for diffusion. On the other hand, non-linear layers are generally based on power maps. The smallest integer that guarantees invertibility and non-linearity is chosen. For instance
is utilized in the case of MiMC. The exponent is chosen if both
and
exist and are both permutations where
Most schemes are based on a round function that applies one linear layer and one non-linear layer, introducing a round constant and/or a subkey:
where c is round constant, M is an invertible MDS matrix and S is the non-linear layer, which can be seen as an s-box. The round function is arranged in a Feistel or SPN structure and iterated. For hash constructions based on the permutations described in the next section, a sponge construction is usually instantiated.
An overview of proposed ZK-focused hash schemes
Many arithmetization-oriented schemes have been proposed in the last 7 years, targeting multi-party computation, fully homomorphic encryption, and zero-knowledge proof applications. We provide a concise overview of constructions focused on prime fields and whose performance has been, mainly or partially measured on R1CS arithmetization. We cite block cipher designs and strategies when they have been used as inspiration to create other hash functions.
One of the first ZK-focused ciphers to be proposed was LowMC (Albrecht et al., 2016). It has received, since then, quite a lot of attention from the cryptanalysis community (see for instance here and here). Inspired by LowMC, MiMC proposes a permutation (that can use the Feistel structure), a block cipher, and a hash function. It relies on the non-linear power map xd with x = 3. The MiMC block cipher was the starting point to improvements in encryption with the GMiMC (Grassi et al., 2019 ) construction and the HadesMiMC strategy (Grassi et al., 2019). MiMC is implemented in libraries such as circomlib and gnark.
The Poseidon hash scheme, proposed after MiMC provided two main advantages: variable-length hashes and instances dedicated for Merkle trees. It is implemented in libraries such as arkworks and circomlib. The authors followed the HadesMiMC approach and the SPN structure, together with the power map xd, with d >= 3 (d = 5 for pairing friendly curves BLS-12-381 and BN-254). They created the Poseidon-pi permutation, based on the Hades design. It contains partial rounds (where the non-linear functions modify one part of the state) and rounds where the non-linear layer modifies the full state. The linear layer is an MDS matrix with dimensions based on the number of field elements processed by the round function.
The Rescue construction (Aly et al.,2019) it is based on a SPN network as Poseidon. However, it utilizes two non-linear layers in the same round with power maps xa and x1/a separated by the linear layer, which consists of a multiplication with an MDS matrix and subkey addition. Neptune is a variant of Poseidon whose non-linear layer reduces the number of multiplications. First, the authors rely on a non-linear layer that uses independent functions and second, they propose to use two different round functions: one for internal rounds and the other one for external rounds. The external round is based on the concatenation of independent s-boxes via Lai-Masey. Finally, the Griffin construction (Grassi et al., 2022) employs s-boxes inspired by Neptune and uses the so-called Horst mode of operation. It provides the best performance when used in plain for a state of field elements t >= 20 among the other candidates. And when using for membership roofs in Merkle tree accumulators it has the smallest R1CS number of constraints.
In the next two sections, we implement the MiMC and Griffin permutations which allows us to describe how other DSLs for writing circuits work. Note that we only implement the permutations for demonstration purposes and that the respective sponge construction should be instantiated for real use. Also, note that to the best of our knowledge, at the time of writing this post, both Neptune and Griffin have been only published on theIACR ePrint website.
Implementing MiMC in Leo
The Leo language is utilized to create applications in the privacy-friendly blockchain Aleo. The proof related to a circuit or application written in Leo is sent as an on-chain transaction so third parties can verify the truth about a certain statement we want to prove. This structure is based on ZEXE. Leo relies on the BLS-12-337 pairing friendly curve and on the Marlin (Chiesa et al., 2019) proof system.
MiMC
In the block cipher construction, MiMC utilizes a permutation polynomial over Fq as round, consisting in the addition of the key, a round constant, and the application of a power map function:
And iterating over the round function F:
…
Using the same permutation in a Feistel network, we can process two field elements if we multiply the numbers of rounds by 2. In this case, the round function is:
Finally, the MIMCP permutation is created by setting k = 0 and the hash function by instantiating a sponge construction with the permutation.
Power maps in the BLS-12-337 curve
Leo uses the scalar field of the BLS-12-377 curve with r = 8444461749428370424248824938781546531375899335154063827935233455917409239041.
In our case, we choose a parameter d = 11. According to Section 5.1 of the MiMC paper we need that the cubing in the round function creates a permutation so gcd(3, p-1) = 1, which is not possible in the case of the scalar field of the BLS-12-377 curve. For d = 5 and d = 7 we have the same problem. We estimate the number of required rounds with the number of rounds with 2 * (log p / log d) for the power map f(x) = xd and the permutation that uses the Feistel structure.
Implementing the MiMCP permutation in Leo
The Leo development environment can be installed from its repository. It only requires a Rust language installation. Via the leo command-line tool, we can build, test, generate and verify proofs for a given circuit or application.
For d = 11, we require 2 * (log p / log 11) = 145 rounds. We hardcode the round constants and implement the Feistel version that can be used in the block cipher with parameter k and in the hash function with k = 0 and by instantiating a sponge construction. We start with the design of the of the non-linear layer, that comprises the addition of a round constant and the power map with d = 11:
functionnon_linear(state: field, constant: field) -> field{
let c: field = state + constant;
let c2: field = c*c;
let c4: field = c2*c2;
let c8: field = c4*c4;
let c11: field = c8*c2*c;
return c11;
}
In Leo, we can create functions using the field data type, that is, an element from the curve scalar field. We add the round constant and perform the power map. The syntax is more similar to Rust than to JS. The application of one round function consists on updating the state, composed of two field elements with the addition of the result of the application of the non-linear layer:
Finally, we can precompute the round constants separately and we can create the permutation:
functionpermutation(state: [field; 2]) -> [field; 2] {
const N_ROUNDS:u32 = 147;
let RC: [field; 147] = [
3865702934124093755943890899496595264675194361091768380145853932420267718340,
1007157542023399026163733618843871954165432315393358131261818260851607860762,
4405765946538921025695035439523237362153599324827654321243952925829102897068,
3664456287923997818199382200327273463939055455139573605615804006507349414661,
[...]
let tmp: field = 0field;
for i in0..N_ROUNDS - 1{
state = round(state, RC[i]);
tmp = state[0];
state[0] = state[1];
state[1] = tmp;
}
state = round(state, RC[N_ROUNDS - 1]);
return state;
}
Leo allows us to create tests on the same file to test our functions, for instance, for the non-linear layer we can do:
@test
functionsbox_test() {
let constant: field = 5943928848779486925441395077146413864173255127001087220085381147547751487102 ;
let state: field = 5324319209727394843353330183529117967230803372202482264714325483223508628524 ;
let check: field = 4817246075678656562069386914259487599241369120264717506466034175518663577036 ;
let result = sbox(state, constant);
console.assert(check == result);
}
and the round function:
@test
functionround_test() {
let state_in: [field; 2] = [
┆ 205590015168576069906775328287417415487799853627397567932093125904979123828,
┆ 6314658282813217945138278251984680094319698463151078319831502705046804707990 ];
let constant: field = 7687545491407243578138660792989370259027838962927279562322213575702987063508;
let result_0: field = 205590015168576069906775328287417415487799853627397567932093125904979123828;
let result_1: field = 4768980667092361968239023698012060630723900845915064763583717922931253545522;
let result = round(state_in, constant);
console.assert(result_0 == result[0]);
console.assert(result_1 == result[1]);
}
We can build the circuit and obtain the number of constraints with leo build:
$ leo build
Build Starting...
Build Compiling main program...
Build Numberof constraints - 735 Build Complete
Done Finished in23 milliseconds
as well as create proving and verification keys and a proof that can be verify correctly via leo run:
So far we have used the circom2 and Leo DSLs. However, there exist other options to describe zkSNARKs circuits using embedded DSLs such as bellman, gnark and arkworks-rs. In this section, we’ll implement the Griffin permutation in gnark using the BLS-12-381 curve. These libraries create an interface between pure R1CS constraints and the operations performed in the circuit e.g. modular multiplications and additions via an API.
Introduction to gnark
We can use the gnark playground or install gnark in our project via go get. In circom2 all the signals are private by default. In gnark, signals are defined via the Circuit struct. For instance, declaring 3 (input) private signals (X0-X2) and 3 (output) public signals (Y0-Y2) is done via:
Once we have defined a circuit using the arithmetic operations of the gnark front end api e.g. via api.Mul(x, x), we can obtain the R1CS representation of our circuit, for a particular curve supported by the library via:
but before creating the circuit for the Griffin permutation, we need to explain its structure.
The Griffin permutation non-linear layer
Grifffin improves the performance of SPN-based schemes by using the so-called Horst mode of operation and the Rescue approach. The Feistel scheme
is replaced by
Griffin utilizes three non-linear functions:
,
, and
where g is a quadratic function.
In our example, we chose the parameters t = 3, R = 12, d = 5, based on the BLS-12-381 field. We apply the permutation to 3 field elements. Note that we are implementing only the Griffin permutation and that we need to instantiate a sponge in order to obtain the associated hashing function. The transformation applied to the three input field elements is the following:
,
, and
The parameters alpha and beta are chosen to be distinct values where a^2 - 4*beta is a quadratic non-residue modulo p. Li is a linear transformation:
For t = 3 we obtain the following non-linear layer implementation:
func non_linear(api frontend.API, x0 frontend.Variable, x1 frontend.Variable, x2 frontend.Variable) (frontend.Variable, frontend.Variable, frontend.Variable) {
alpha, _ := new(big.Int).SetString("20950244155795017333954742965657628047481163604901233004908207073969011285354", 10)
beta, _ := new(big.Int).SetString("3710185818436319233594998810848289882480745979515096857371562288200759554874", 10)
y0 := add_chain_exp_d_inv(api, x0)
y1 := exp_d(api, x1)
// l for t = 3 l := api.Add(y0, y1)
lq := api.Mul(l, l)
l = api.Mul(l, alpha)
l = api.Add(l, lq)
l = api.Add(l, beta)
y2 := api.Mul(x2, l)
return y0, y1, y2
}
The power map 1/d
At the time of writing this post, gnark does not provide a gadget for native modular exponentiation (see for instance https://github.com/ConsenSys/gnark/issues/309). We need to implement the exponentation of 1/d, that is the modular inverse of 5 mod (p -1), used on the second field element of the input in the permutation, which corresponds to z = x^0x2e5f0fbadd72321ce14a56699d73f002217f0e679998f19933333332cccccccd. Since the gnark API provides the modular multiplication operation, one alternative could be to implement a variant of the square-and-multiply approach, which would yield a number of constraints based on the number of multiplication operations (more precisely, 254 doublings and 130 multiplications = 384 multiplication gates). On other other hand, since we are dealing with a fixed exponent operation, we can implement the power map using a short addition chain. In this case, we have used addchain to generate an addition chain for 1/d based on 305 multiplications and created a template for gnark.
The Griffin permutation linear layer
The linear layer of Griffin for t = 3 is based on the circulant matrix cir(2, 1, 1), which results in adding the sum of the 3 input field elements to each of the elements of the state, that is, via the matrix:
which can be performed in gnark via:
func mds_t_3_no_rc(api frontend.API, x0 frontend.Variable, x1 frontend.Variable, x2 frontend.Variable) (frontend.Variable, frontend.Variable, frontend.Variable) {
/* for t = 3, M = circ(2,1,1)
┆ for state input (a, b, c) output is =
┆ | 2a + b + c |
┆ | a + 2b + c |
┆ | a + b + 2c |
*/sum := api.Add(x0, x1, x2)
return api.Add(sum, x0), api.Add(sum, x1), api.Add(sum, x2)
The permutation
Finally, we can hardcode all the round constants and perform the 12 rounds:
Ingredients for a checklist when auditing circuits
Based on the first part of this post and this one, I have prepared a list of checks that could be used for validating implementations of zk-oriented schemes. Some of them are based on the DSL it self , others are based on the very nature of the zkSNARKs circuits themselves and finally, other mistakes can appear based on the lack of input validation of the upper layers in so-called zk-distributed applications.
Overflows not validated in upper layers
Every arithmetic operation within a circuit is performed mod q, where Fq is the field of the pairing-friendly curve utilized. That means, that if it is possible to satisfy a circuit with inputs x0, x1, it is also possible to satisfy the same circuit with inputs (x0 + n*q, x1 + n*q). Even if this fact seems trivial, an application that uses a zkSNARK circuit with authorization purposes that don’t take this fact into account can believe that is accepting different valid inputs where at the same type they correspond to the same input. This fact is directly related to the next point, “collisions” in hash functions.
“Collisions” in hash functions when input size is not validated
The same overflow example presented in the point above can be utilized for creating “collisions” in hash functions if the input is not validated in a zk-app. We can show this fact using the gnark playground. It contains an example using MiMC for proving the knowledge of a secret 0xdeadf00d with digest 5198853307513511565221857855889129613353124614036601136339058862251852610180.
// Welcome to the gnark playground!package main
import (
"github.com/consensys/gnark/frontend""github.com/consensys/gnark/std/hash/mimc")
// gnark is a zk-SNARK library written in Go. Circuits are regular structs.// The inputs must be of type frontend.Variable and make up the witness.// The witness has a// * secret part --> known to the prover only// * public part --> known to the prover and the verifiertype Circuit struct {
Secret frontend.Variable // pre-image of the hash secret known to the prover only Hash frontend.Variable `gnark:",public"`// hash of the secret known to all}
// Define declares the circuit logic. The compiler then produces a list of constraints// which must be satisfied (valid witness) in order to create a valid zk-SNARK// This circuit proves knowledge of a pre-image such that hash(secret) == hashfunc (circuit *Circuit) Define(api frontend.API) error {
// hash function mimc, _ := mimc.NewMiMC(api)
// hash the secret mimc.Write(circuit.Secret)
// ensure hashes match api.AssertIsEqual(circuit.Hash, mimc.Sum())
return nil
}
-- witness.json --
{
"Secret": "0xdeadf00d",
"Hash": "5198853307513511565221857855889129613353124614036601136339058862251852610180"}
However, if the input size is not validated in the application that uses the circuit, we can create other valid inputs, for instance 5198853307513511565221857855889129613353124614036601136339058862251852610180 + q*4= 180304796282227713343193103817947330321740039817364875885924692354858320575116 that also satisfies the circuit. One way of avoiding this type of problems can be by enforcing input validation in the upper layer that uses the circuit. Moreover, DSLs such as circom2 allows inputs made of bits which can be used for accepting an input specific length.
Utilization of dangerous operators
Some languages include operators that can be problematic when used incorrectly. In a DSL we could expect that every assign operation including an arithmetic operator creates a constraint. This is the case when using the <== operator in circom2. However, it can be possible to assign a value including an arithmetic operation with the operator <--. In that case, a constraint is not created, which can be exploited for creating proofs with invalid inputs that pass as valid.
Finding errors in unconstrained R1CS circuits can be automated using tools such as Franklyn Wang‘s Ecne project, a tool which I contributed to during the 0xPARC 2nd learning group.
Incorrect parameters in zk-oriented schemes
Many encryption and hash schemes designed for zero-knowledge applications require round constants generated with specific properties as well as parameters (such as alpha and beta in Griffin). These parameters are usually hardcoded to reduce the number of constraints in a circuit. Another example is choosing a valid value d in the power maps according to the pairing-friendly elliptic curve utilized.
Roman Walch, Franklyn Wang (Ecne Project), 0xPARC community.
Last update: 14th July 2022
2022
Crypto
Cryptography
Data privacy
Defense
Quantum computing
July 5, 2022
NIST Announces First Quantum-Resistant Cryptographic Standards, PQC End of 3rd Evaluation Round
No items found.
Kudelski Security Team
After a long process started in 2016, today NIST announced the first standardized cryptographic algorithms designed to protect IT systems against future quantum attacks. Here is the list of the first winners of the competition:
For digital signatures:
CRYSTALS-Dilithium
Falcon
SPHINCS+
For KEMs:
CRYSTALS-KYBER
Additionally, the following candidate KEM algorithms will advance to the 4th and final round, even though they have not been standardized yet:
BIKE
Classic McEliece
HQC
SIKE
This is exciting news, as it marks a fundamental milestone in a very long process that the cryptography and security community has been following for many years. Quantum computers are rapidly advancing to a state of maturity that will allow soon to solve real-world problems in chemistry, physics, logistics, etc. Although cryptanalytic applications of quantum computers are probably still far away, given the long lifespan of security applications and the slow process of updating IT systems, businesses and governments have started to worry about quantum attacks for a while already. What was holding many stakeholders off from proactively starting a quantum-resistant strategy for their products and services was the lack of accredited international cryptographic standards. Now this obstacle has been removed, so we expect (and we welcome) a wave of renewed interest in quantum-resistant applications.
2022
Cloud-native-security
June 30, 2022
Azure Compliance-as-Code unit-testing with Golang
No items found.
Romain Aviolat
Infrastructure-as-Code (IaC) is great. It allows teams to deploy infrastructure quickly in a consistent and repeatable manner and when coupled with a proper CI/CD process (linting, SAST (Static Application Security Testing), 4-eyes reviews, multi-env, …) it creates a powerful security framework for platform and development teams.
However as great as IaC is, it does not prevent users from making mistakes; it is easy to wrongly expose a service and thus increase your attack surface or to deploy it in a way that conflicts with your compliance requirements.
Luckily Cloud providers offer guardrail functionalities to catch those mistakes and to enforce your compliance requirements.
Azure provides it under the Azure Policy feature; for Google it is called Organization Policies and for AWS (Amazon Web Services) it is Service Control Policies. The implementation methods and features differ between the different cloud providers, but the idea is the same; provide central control over the maximum available permissions for the accounts in your organization.
In this blog post I’ll cover how you can manage these guardrails as-code and how you can code unit-tests to validate them. We will focus on the Azure platform, but it could be easily reproduced on the others.
(all the code present is this blog-post is available on the following Github repository)
Scoping guardrails
You need to start somewhere, and the blank page syndrome can be hard to overcome… My recommendation is to start with low hanging fruits. First, things that you never want to see happening in your production environment no matter what.
Ideally you should also pick things that will have little to no impact on your platform and development teams – it’s always frustrating to rollback or make people angry at the beginning of a new project. Also, keep in mind that you will need the support of these teams to progress on your Cloud-native security journey, so it is best if you have their buy-in day 1.
We’ll start with two simple use-cases:
We’ll forbid the deployment of resources in certain regions.
We’ll forbid certain source-addresses / destination ports patterns when creating Network Security Groups (NSG).
Now we need to define where in the accounts hierarchy we want to apply these policies. Azure recommends organizing Subscriptions under Management Groups. In this blog post that’s where we’ll assign them, but they could be just as readily assigned at the Subscriptions level or at the Resource Groups level as well. Assigning policies at the top of the tree means that all the objects downwards will inherit them.
Creating policies
Policies can be defined inside the Azure Portal Policy page under “Authoring / Definition” but we’ll do it as-code using Terraform today.
We’ll focus on the policy for forbidden regions here but the code for both is available here.
Notes:
As you can see this policy takes parameters (“deniedRegions” array) as input so it’s in fact a template.
In the policies definition code we have set the “effect” to “deny” which means that resources meeting these specific conditions will be denied at creation-time.
A smart way to implement policies is to set them in “audit” mode first to identify the potential impact and in “deny” mode to enforce them afterwards.
Assigning policies
Now that the policies are created, we need to assign them to our Management Group (“Authoring / Assignments in the Azure portal). Without an assignation a policy has no effect.
The “deniedRegions” key inside the parameters block, this is where we can set the variable that is applied inside the policy definition.
Something also useful is the ability to define a non-compliance error message inside the policy assignment resource. This allows us to answer with a meaningful error message for the users when they deploy non-compliance resources, and it gives us the flexibility to define different error messages for the different assignments you may define (per subscription / teams, resources groups).
Testing the policies
Now that we have created and assigned our policies we can do a quick test from the Azure portal, by trying to create a new NSG rule that voids the policy or by deploying a resource in a forbidden region.
Deploying a NSG that voids the NSG policy
Deploying a resource in a forbidden region
We can see that our policies prevented the deployment of the resources, and that it did so during the evaluation process of the resource creation. This is quite powerful because it will warn users even before deploying the offending resources, instead of crashing with an error message at deployment-time.
The same will happen if we try to deploy the resource as-code, we will find the non-compliance error message inside the query response body.
Managing exemptions
A good policy framework must also support exemptions for certain rare use cases. Azure Policy provides that out-of-the box. We won’t cover exemptions in this blog post but they follow the same logic as policies assignments, you define a scope, a reason and optionally an expiration date for the exemption and that’s it.
I could have stopped here, but I wanted to go a bit further than that. These policies are working as expected, but I still had the following questions open in my mind. How to make sure that:
The policy really blocks what it’s supposed to?
The policy behaves properly over time? For example, if some wrongly scoped exemptions are created?
The policy does not block something it is not supposed to?
The expected policy prevents deployment of a non-compliant resource in case there is overlapping policies?
Some of the questions above could be answered by the principle of least privilege, locking in the policies at the highest org-level and granting access only to certain super-admins. With infrastructure as-code, however, it is usually a service account that is used to push the changes on the platform and even with four-eye reviews, a mistake could happen.
To answer all these questions, I decided to implement unit tests. Initially I thought about doing them using Terraform code, but it was a bit cumbersome to catch and parse error messages and would mean that I had to wrap some bash or Golang around the Terraform code to achieve what I wanted to do.
Instead, I decided to implement the resource creation process using Golang code (leveraging the Azure SDK for Golang) and simply define unit tests using the standard testing package.
Here’s an extract of the testing scenarios for the forbidden regions (full code here).
And here’s an extract of the logic to iterate over all the tests (full code here):
Here’s an extract of the testing scenarios for the forbidden NSGs (full code here).
And here is how it looks like when being executed (here the NSG tests):
We can see that all the tests successfully passed as expected.
Wrapping up
In this blog post we saw how to improve our Cloud-native security by implementing guardrails as-code leveraging Azure Policies.
We also saw how to make sure that these policies remain consistent over-time by coding some unit-tests in Golang.
It is understood that all the Terraform code and the unit tests must be part of steps in a Continuous-Integration/Continuous-Deployment (CI/CD) pipeline.
Pretty Good Privacy (PGP) and the open source implementation GNU Privacy Guard (GPG) are encryption solutions following the OpenPGP standard. Even if GPG has been criticized in the past, it is widely used and deployed and has been publicly reviewed for many years. For example, GnuPG VS-Desktop has been recently approved by the German government to secure data at the VS-NfD (restricted) level. Thus it is used in practice to protect sensitive data, for example, to sign and encrypt emails, sign commits, or authenticate packages for several Linux distributions. To decrypt a message, the following command can be used:
$ gpg -d clear.gpg
gpg: encrypted with3072-bit RSA key, ID 6F2C79C919966FC1, created 2021-07-21"Test key <[email protected]>"Hello GPG
Hello GPG
The first time the decryption is called, the system asks the user for their passphrase to decrypt the private key needed to decrypt the file.
Then for future decryption attempts, the passphrase is not asked but read from cache. The same mechanism is used for symmetric-key encryption. The cache time to live has a default value of 10 minutes. After the time to live elapsed, the cached item is cleared from memory.
To avoid having key material directly in the clear in memory, GPG encapsulates such key material before storing it in memory. The idea of that is that if a TPM is available, then the encapsulation key can be stored in a safe memory area. However, TPMs are usually not used, and the encapsulation key stays in regular memory.
A cached item is stored in the ITEM structure. We find this structure in gnupg/agent/cache.c (GPG version 2.3.4):
Cached item linked list
The ITEM structure is a linked list containing the cached item address and additional data. Among them, there are the time of creation and time of last access. These values are unix epoch times, the number of seconds elapsed since January 1, 1970. Then there is the time to live (ttl) field which is the number of seconds gpg-agent has to keep the item in cache. By default it is set to 10 minutes (0x0258 seconds). If gpg-agent found that the last accessed time is older than the time to live, the item is cleared from cache. After that we have the address of a secret_data_s structure. The secret_data_s structure contains the length of the cached item in bytes followed by the encrypted item with AES in key wrap mode. GnuPG uses AES key wrap mode of operation to encapsulate key material in memory as defined in RFC 3394. The AES key wrap algorithm is used to encrypt (wrap) keys or secrets with another key. It is used in several solutions like Apple FileVault 2 or Cryptomator. The mode uses two 64-bit blocks concatenated together as input of AES encryption:
First iteration of AES key wrap
This operation is iterated 6 times, and the final R values obtained are outputted as the ciphertext. Decryption works in exactly the same way but in reverse order. The initialization vector (IV) can be any value but the RFC default value is 0xa6a6a6a6a6a6a6a6. It allows for verification of the integrity of the decrypted key after the decryption. If the last decrypted block yields a value that starts with the IV, decryption is considered correct as long as no other error is returned. GPG uses the implementation of AES key wrap provided by the Libgcrypt library. In GPG, the cached item encryption is used to prevent attackers from simply grepping for passphrases in memory as commented in gnupg/agent/cache.c (GPG version 2.3.4):
However, as we will see later, someone who has access to the memory can also retrieve the encryption key and decrypt cached items anyway. To avoid having sensitive values left in memory after processing, Libgcrypt deletes those values when they are not used anymore. For example, a variable is wiped with the function wipememory and the stack is cleaned with the function _gcry_burn_stack. In Libgcrypt, the function _gcry_cipher_aeswrap_decryptlibgcrypt/cipher/cipher-aeswrap.c on line 81) did not clean a temporary variable containing the last decrypted block. Suppose we use GPG to decrypt some cleartext using a passphrase. At the end of the cached item decryption, the temporary variable contains the IV value 0xa6a6a6a6a6a6a6a6 followed by the first 8 bytes of the passphrase. For example, if a dump of gpg-agent’s memory using gcore or a dump of the whole system memory using LiME can be obtained, then, we should retrieve the constant 0xa6a6a6a6a6a6a6a6 in memory, next to the first 8 bytes of the passphrase. We reported this problem to GPG maintainers. This was quickly corrected in Libgcrypt 1.8.9 and future versions should not be affected by this issue.
Nevertheless, we investigated more to understand if it is possible to decrypt completely the passphrase in cache. We saw that each cached entry has two timestamps created and accessed of type time_t. This information can be leveraged to search for such patterns in memory and retrieve the location of cache_item_s instances. If we can estimate the time of the creation of the cached item, we can search for masked timestamps concatenated in memory followed by the time to live value. For example, the following regular expression matches all timestamps created after July 27, 2021 12:45:52 PM and before February 6, 2022 5:06:08 PM with a time to live of 10 minutes:
To further reduce the number of false positives during the search, for each match, the created time can be checked to be less than or equal to the accessed time. Then, as soon as the ITEM structure has been found, we can access the secret_data_s structure.
To recover the encryption key, we used a known method to recover AES keys in memory. In AES, before data is encrypted, the AES key schedule is used to derive 11 subkeys that are used later in the algorithm.
AES key schedule algorithm
These subkeys are usually stored consecutively in RAM and there are relations between each consecutive subkeys. Thus, we scan the memory byte per byte trying to see if at this position the AES key schedule relation are verified. If it is the case for two consecutive rounds, there is a very high probability that there are subkeys stored at this location. We scan the process memory until we find a 128-bit expanded AES key. Then we use this key to decrypt the cached item. If the integrity of AES key wrap is verified we know we have properly decrypted the cached item and recovered the passphrase.
At this point, we had everything we needed to implement our solution. Volatility is a widely used forensics framework. It is used to analyze volatile memory dump artifacts to extract data. For example, it has been used in the past to recover Bitlocker volume encryption keys while they are in RAM or to solve challenges of previous SSTIC editions. The framework is highly customizable and allows writing plugins in Python to fit specific needs. Therefore, we developed two plugins for Volatility3. The first plugin retrieves partial (or complete, up to 8 characters) passphrases from memory by searching in gpg-agent‘s memory the constant IV of aes-wrap. This plugin would not work on versions of GPG later than version 2.3.4.
The first 8 bytes of the passphrase were found in the clear in memory. The second plugin retrieves cached items and cache encryption keys from memory and therefore helps recover plaintexts. Here is an example of usage on an Ubuntu 21.10 VM dump:
The plugin successfully found the entire passphrase my_passphrase in memory. The first plugin execution took 6.4 seconds and the second 59.7 seconds on an Intel Core i7-7600U CPU for a 1GB RAM dump.
Memory forensics may be used during a criminal investigation to analyze memory dumps obtained during a search and seizure. After the data has been copied, the investigator may need to obtain the passphrases stored encrypted in cached items to further decrypt conversations. These techniques may also be applied to investigate virtual machines stored remotely in servers that are seized.
Ransomware is a common problem nowadays. These malicious software encrypt files on an infected machine and ask the owner for a ransom so that they can recover their files. It happens that some ransomware rely on well studied tools to encrypt a user’s data. Ransomware such as KeyBTC, VaultCrypt or Qwerty use GPG to encrypt files. In the event that a victim of such a ransomware just noticed what happened when they get infected, the victim or the incident response team could make a memory dump of the whole system and later retrieve the password or decryption key from memory. Thus, thwarting the ransomware threat and retrieving the original files without having to pay a ransom at all. Note that the ransomware would have to rely on symmetric encryption for this to work (gpg --symmetric) and, so far, we have not found any ransomware relying on GPG symmetric encryption.
To conclude, we have analyzed a bug in Libgcrypt where after cleaning memory, it was still possible to read 8 bytes of the passphrase in the clear from a memory dump. We have further analyzed how to decrypt cached items stored in GPG memory. Our work highlights that GPG is a solid encryption solution, but it should be used in conjunction with a TPM or a secure enclave solution to harden the security against physical attacks.
2022
Security Advisory
May 20, 2022
High Severity VMware Vulnerabilities Under Active Exploitation
No items found.
Kudelski Security Team
This bulletin was written by Travis Holland and Eric Dodge of the Kudelski Security Threat Detection & Research Team
Executive Summary
On May 18th, 2022, the U.S Cybersecurity and Infrastructure Security Agency (CISA) released Emergency Directive 22-03 requiring U.S Federal Government agencies to patch VMware vulnerabilities under active exploitation or vulnerabilities CISA expects to be exploited in the next 48 hours. Due to active exploitation of vulnerabilities made public in April, and additional vulnerabilities published in May, the Cyber Fusion Center strongly advises all organizations with vulnerable instances to take immediate action.
VMware has released two security advisories related to vulnerabilities that may be exploited by Nation State and advanced threat actors. VMSA-2022-0014 was issued on May 18th and contains detailed for two newly disclosed vulnerabilities: An authentication bypass issue, assigned, CVE-2022-22972 which impacts VMware Workspace ONE Access, Identity Manager and vRealize Automation, Additionally, a Privilege Escalation vulnerability was also disclosed, the vulnerability was assigned CVE-2022-22973, and impacts VMware Workspace ONE Access and Identity Manager. At this time neither are known to have been exploited in the wild, however, CISA, VMware, and the CFC expect threat actors to begin exploitation of these issues shortly.
In April of 2022, VMware produced a separate security advisory, VMSA-2022-0011, which contained details of eight (8) vulnerabilities, ranging from critical to moderate. The vulnerabilities disclosed in April include remote code execution, authentication bypass, local privilege escalation issues, and more. The vulnerabilities disclosed in April impact a wide range of VMware products, including VMware Workspace ONE Access, Identity Manager, and vRealize Automation. Some of the vulnerabilities disclosed in April are known to havebeen actively exploited in the wild by a wide range of threat actors. VMware has provided patches and workarounds for all identified vulnerabilities; however, the CFC strongly advises organizations to apply patches rather than leverage temporary workarounds as the workarounds can have a noticeable impact on business operations.
For additional details about these vulnerabilities, including versions of VMware software impacted, please review the rest of this bulletin.
Summary of VMware Product Versions Impacted by April and May 2022 Vulnerabilities
Below is a table that highlights which VMware products are impacted by the vulnerabilities disclosed by VMware throughout the months of April and May. For additional details on these vulnerabilities, please review the contents of this bulletin and, if applicable, any linked sources and content.
VMware Vulnerabilities Disclosed in May 2022 (VMSA 2022-0014)
On May 18th VMware released an advisory for two new vulnerabilities: CVE-2022-22972 and CVE-2022-22973. Those are broken down into an authentication bypass, and a local privilege escalation issue. They require network/local access to the respective VMware product User Interfaces in order to properly exploit the vulnerabilities. Due to the nature of these vulnerabilities, CISA has pushed an emergency directive requiring U.S Government Agencies to patch or mitigate these issues within 5 days. The vulnerabilities are not currently being exploited; it is expected to start occurring within the next 48 hours based on previous reverse engineering of similar vulnerabilities from April 2022.
CVE-2022-22972 is a critical severity authentication bypass vulnerability with a CVSSv3 score of 9.8. This vulnerability allows authentication bypass impacting any local domain users and requiring network access to the software’s User Interface.
Note that for some software systems, such as VMware Workspace ONE Access or VMware Identity manager, the User Interfaces may be intentionally exposed to the internet and thus should be prioritized for remediation.
Component(s) Impacted
Workspace ONE Access
Identity Manager
vRealize Automation
Local Privilege Escalation (CVE-2022-22973)
CVE-2022-22973 is an important local privilege escalation vulnerability with a CVSSv3 score of 7.8. This vulnerability allows a malicious actor with local access to escalate privileges to ‘root
Component(s) Impacted
Workspace ONE Access
Identity Manage
Resolution/Mitigation
VMware recommends patching as soon as possible to remediate CVE-2022-22972 and CVE-2022-22973. The patch instructions can be found in KB88438, also provided below in the sources section. There currently is a workaround; however, it may have an impact on business operations, and patching is highly recommended. The workaround will make admins unable to log into Workspace ONE console via the local admin account. More information on performing the workaround can be found in KB8843; which is available below in the sources section.
VMware Vulnerabilities Disclosed in April 2022 (VMSA 2022-0011)
Multiple vulnerabilities have been identified to impact several VMware products including Workspace ONE Access, Identity Manager, vRealize Automation, Cloud Foundation and vRealize Suite Lifecycle Manager. The Cyber Fusion Center is aware of several threat actors actively exploiting these vulnerabilities for initial access and strongly recommends organizations with vulnerable versions of the software assume breach and investigate deployments for potential compromise. VMware has provided patches to remediate all identified vulnerabilities and patches should be applied immediately.
Details regarding the vulnerabilities disclosed by
Server-side Template Injection (CVE-2022-22954)
Critical severity remote code execution vulnerability exploiting server-side template injection with CVSSv3 score of 9.8. This vulnerability allows a malicious actor with network access the ability to trigger a server-side template injection potentially allowing code execution. This vulnerability is known to have been used by several threat actors to gain initial access to organizations with these VMware products deployed.
Critical severity authentication bypass vulnerability in the OAuth2 ACS Framework with a CVSSv3 score of 9.8. This vulnerability allows authentication bypass which allows the malicious actor the ability to execute any operation due to exposed endpoints in the authentication framework.
Critical severity remote code execution vulnerabilities with a CVSSv3 score of 9.1. This vulnerability allows code execution by triggering deserialization of untrusted data through a malicious JDBC URI.
Component(s) Impacted
Workspace ONE Access
Identity Manager
VRealize Automation
Cross Site Request Forgery (CVE-2022-22959)
Important severity cross site request forgery vulnerability with a CVSSv3 score of 8.8. This vulnerability allows a malicious actor to trick a user into validating a malicious JDBC URI through cross site request forgery.
Component(s) Impacted
Workspace ONE Access
Identity Manager
VRealize Automation
Local Privilege Escalation (CVE-2022-22960)
Important severity local privilege escalation vulnerability with a CVSSv3 score of 7.8. This vulnerability allows a malicious actor with local access to escalate privileges to ‘root.’
Component(s) Impacted
Workspace ONE Access
Identity Manager
VRealize Automation
Information Disclosure (CVE-2022-22961)
Moderate severity information disclosure vulnerability with a CVSSv3 score of 5.3. This vulnerability allows a malicious actor with remote access to leak the hostname of the targeted system potentially leading to targeting victims.
Component(s) Impacted
Workspace ONE Access
Identity Manager
VRealize Automation
Resolution/Mitigation
VMware recommends applying available patches as soon as possible to the vulnerabilities described in this bulletin. The patch instructions can be found in KB88099, also provided below in the sources section.
VMware has provided temporary workarounds; however, they is a high likelihood that these workarounds will impact business operation. As such, the CFC strongly recommends applying patches as soon as possible rather than applying workarounds. Information on performing the workaround can be found in KB88098; which is available below in the sources section.
Active Directory Domain Services Elevation of Privilege Vulnerability
No items found.
Kudelski Security Team
This bulletin was written by Michal Nowakowski of the Kudelski Security Threat Detection & Research Team
Update June 1st, 2022, 1830h UTC (2.30PM EDT)
Microsoft released on May 19th an out-of-band patch to address the authentication issues encountered on Windows Servers with Domain Controller service enabled induced by the initial patch released on May 10th. Please follow Microsoft’s guidance on how to update your Domain Controllers.
Update May 16th, 2022, 1800h UTC (2PM EDT)
Microsoft and the U.S CyberSecurity & Infrastructure Security Agency (CISA) recommend that organizations avoid installing some patches released on May 10th on servers acting as domain controllers. Patches provided by Microsoft on May 10th are causing some authentication issues to users. As such, Microsoft recommends currently only installing the patch on Windows Workstations and Windows Servers without Domain Controller service enabled.
The patches causing issues include the first patches for the vulnerability described in this advisory (CVE-2022-26923). Additionally other patches released by Microsoft (such as a patch for CVE-2022-26925, known as PetitPotam) appear to also cause authentication issues.
Organizations who may have already deployed Microsoft’s patches for the Certificate Services vulnerability described in this blog may consider changing the registry key entry named StrongCertificateBindingEnforcement (described in the “Solutions & Patches” section of this blog post) to a value of “0” in order to disable certificate mapping checks temporarily – while Microsoft works on addressing issues caused by this patch. Alternatively, organizations may choose to review windows event audit logs to identify offending certificates, and then manually map certificates that are causing authentication failures.
This blog post will be updated with the most recent information about this vulnerability as the situation progresses.
Summary
On May 10th Microsoft recently disclosed an Active Directory Domain Privilege Escalation Vulnerability (CVE-2022-26923) which was part of May 2022 Security Updates. It is a high severity vulnerability, which could allow any domain user to escalate privileges to that of a Domain Administrator if Active Directory Certificate Services (AD CS) are running on the domain.
This vulnerability stems from a bug in how machine certificates are issued by Active Directory Certificate Services which fails to check the if the SAM Account Name of the entity requesting a certificate matches the dNSHostName attribute of an issued certificate. Additionally, AD Certificate Services did not explicitly check for a “$” at the end of an account name (used to denote a machine account). By abusing this vulnerability, an attacker can request (& receive) a certificate for the DNS hostname of a domain controller. This certificate can be abused to impersonate a domain controller.
There are already numbers of publicly available Proof of Concept (PoC) exploits for the vulnerability, including detailed write-ups on how it works and how to abuse it. Microsoft has chosen to patch this vulnerability in a staged manner, first enabling auditing of suspicious or misconfigured certificates, and then later disallowing authentication using such certificates. Microsoft’s decision was made in order to prevent potential impact on a client’s Active Directory environment. The patches released May 10th enable additional auditing of certificates that may have been issued in error or could be malicious.
The Cyber Fusion Center strongly recommends that organizations who run Active Directory Certificate Services apply Microsoft’s provided patches as quickly as possible. Applying such patches will enable organizations to begin auditing certificates that may have been issued incorrectly – or malicious certificates that may have been issued due to this vulnerability.
For details regarding how to immediately enable features that block such misconfigured or malicious certificates, please review the patches and solution section of this advisory. For temporary mitigation options, please review the mitigations section of this advisory.
Attack / Vulnerability Details
To successfully exploit this Privilege Escalation vulnerability and perform DCSync attack, an adversary would perform the following steps:
Create a Machine Account on the domain
Note: by default, any domain authenticated user can add up to 10 machines accounts to a domain
Modify the dNSHostName attribute of the newly created machine account to be DNS hostname of Domain Controller
Request & receive a certificate using modified attributes in machine account
Authenticate with requested certificate
Attackers in possession of such a certificate can retrieve a hash of the domain controller’s domain account. This hash could then be used to impersonate a domain controller and replicate all domain user’s password data (known as a “DCSync Attack”) to a system the attacker controls.
Solutions & Patches
Microsoft has released patches for this vulnerability in a staggered fashion in order to limit impact for organizations who may have misconfigured certificates. The patches released on May 10th, enable auditing to help organizations identify misconfigured or malicious certificates that are being actively used for authentication and do not prevent the usage of malicious certificates by default. Organizations can choose to enable enforcement.
Microsoft recommends that organizations leave AD Certificate Services / Authentication systems in “audit mode” for at least a month and work to review audit logs related to misconfigured certificates. Once organizations are confident that there will be no or little operational impact to enforcing additional security requirements to use certificates for authentication, they can enable enforcement by editing the following registry key (only available after the patch is installed):
1 – Checks if there is a strong certificate mapping. If yes, authentication is allowed. Otherwise, the KDC will check if the certificate has the new SID extension and validate it. If this extension is not present, authentication is allowed if the user account predates the certificate.
2 – Checks if there’s a strong certificate mapping. If yes, authentication is allowed. Otherwise, the KDC will check if the certificate has the new SID extension and validate it. If this extension is not present, authentication is denied.
0 – Disables strong certificate mapping check. Not recommended.
Note: Microsoft will issue a patch in May 2023 to automatically enable enforcement
The CFC strongly recommends organizations deploy the May 10th patch and review audit logs for misconfigured certificates prior to this deadline.
Mitigations
Organizations who are not able to patch their Active Directory Certificate Services systems, could potentially consider hardening Active Directory Certificate Services (AD CS) environment by restricting certificate enrollment. Additionally, organizations may consider disabling the ability for regular / non-administrative domain users from enrolling new machine accounts to the domain.
As mentioned previously, the ability for regular users to enroll new machine accounts is enabled by default. Organizations can modify their Active Directory schema by modifying the “MS-DS-Machine-Account-Quota” attribute to disallow non-privileged users from enrolling any machine accounts
Note: Modifying the MS-DS-Machine-Account-Quota attribute does not necessarily prevent exploitation but reduces your overall attack surface for this vulnerability.
What the Cyber Fusion Center is doing
To obtain visibility into any activity potential exploit or attack activity related to the vulnerability described in this document, the Cyber Fusion Center is investigating additional detection capabilities identifying the manipulation of the servicePrincipalName attribute performed using the setspn.exe process. This process is used either to delete values that contain dNSHostNam or add new ones.
The CFC will continue to test and validate its detection methodology, once validated, the CFC will begin deployment of the detection to all relevant clients with Active Directory Certificate Services (AD CS) enabled. MDR ONE Clients will have detection capabilities as soon as the detection is finalized.
In parallel, the latest Windows Security Update added several new Event IDs which are currently being investigated by the Detection Engineering to understand how they could be leveraged for detection in the future.
Practical bruteforce of AES-1024 military grade encryption
No items found.
Kudelski Security Team
I recently presented work on the analysis of a file encryption solution that claimed to implement “AES-1024 military grade encryption“. Spoiler alert: I did not break AES, and this work does not concern the security of AES. You may find advanced research regarding this topic.
This project started during a forensic analysis. One of my colleagues came with a USB stick containing a vault encrypted with SanDisk Secure Access software. He asked me if it was possible to bruteforce the password of the vault to recover the content. I did not know this software thus, I started to research. It appeared that this solution is distributed by Sandisk by default on any storage device you buy from them.
Sandisk SecureAccess
The solution is convenient, it allows a user to run the binary on the disk and after entering her correct password her vault is unlocked and the files are accessible. Once the software is closed, the files are encrypted back and not accessible anymore. So far nothing uncommon, but one thing drew my attention. In the Options menu, you can choose your “Preferred encryption method“.
I could choose ( if I would bought the premium version of the software) between several methods: “AES 128 bit“, “AES 256 bit“, “AES 512 bit” and “AES 1024 bit“. It was surprising to me since AES keys are defined in the standard to be either 128, 192 or 256-bit long but not 512 nor 1024 bits. Thus I was definitely interested to know what was behind this solution.
I dug a bit deeper and I discovered that the solution is developed for SanDisk by a company called ENCSecurity. The interesting part is that the solution is general and distributed to Sony and Lexar as well under different names. ENCSecurity also sells their own paying version with more options. I was surprised that the solution was not supported yet by John the ripper nor Hascat. In addition, the security claims of their website are really strong.
ENCSecurity website
They claimed to provide “Ultimate encryption using 1024 bit AES keys, Military grade”. Thus for all those reasons, I decided to analyze the solution to figure out how it was implemented.
The binary is a PE packed with UPX. PE explorer allowed me to unpack it and still run properly. In the ENCSecurity version of the software, an option allows enabling the log of the application. At the beginning of the log I had:
05:11:42.633 D utils.cpp 372 showMessage returned 005:11:42.633 I encmainwindow.cpp 738 Starting ENCDataVault70 version: 7.1.1W
05:11:42.633 I encmainwindow.cpp 739Date: 28.04.202105:1105:11:42.633 I encmainwindow.cpp 740 Qt library version: 5.9.605:11:42.638 I encmainwindow.cpp 741 OpenSSL system library: OpenSSL 1.0.2q 20 Nov 201805:11:42.638 I encmainwindow.cpp 742 OpenSSL version: OpenSSL 1.0.2q-fips 20 Nov 201805:11:42.638 I enclogging.cpp 322 Application name: "ENCDataVault70"
I knew it used OpenSSL and Qt libraries and I got the version number as well. It allowed me to create a Ghidra Function ID database on the same libraries and Ghidra matched some of the function signatures in binary. It simplified a lot the analysis since all the Qt functions could be left apart since they concern the GUI and the interesting functions use OpenSSL for Cryptography algorithms.
In fact from a general point of view, I was analyzing a password hash function. The function takes as input a user password and hashes it to a key which is later used to encrypt or decrypt data. Usually, the password hash function takes as input a unique and randomly generated salt to avoid precomputed attacks like dictionary or rainbow table attacks. Another common parameter of the hash function is the iterations number which allows to adapt the work factor. The higher the iteration number is the longer it will takes to compute the hash and thus, the harder it will to bruteforce the password for an attacker. Currently the are various recommended algorithms like: PBKDF2, Scrypt or Argon2. Argon2 is the winner of the Password Hashing Competition and is now considered as the state of the art for password hashing.
For this analysis, I only needed to focus on PBKDF2. Its design is simple:
It uses a HMAC function with the user password used as the input key. The input message is simply the salt concatenated with the constant 1. In the previous figure, c is the number of iterations. At the end we obtain a key. However with the current construction, the key cannot be larger that the output of the HMAC. So how do we construct 1024-bit keys? PBKDF1 was originally designed with this limitation. However, in PBKDF2, the solution was found to iterate several time the construction but with the input message to be the salt concatenated with constant 1 to obtain the first key part key[1], then the constant 2 is used to obtain the second key part key[2] and so on … Then the derived key is simply the concatenation of all the key part obtained during the iterations.
If we go back to our binary, the key derivation function was not identified directly by Ghidra Function ID and I had to reverse it manually. Thankfully, some calls to the MD5 hash function were identified under several layers of calls. Finally, after some efforts, I was able to reverse it. Here is how it looks:
The design is similar to PBKDF2 but they used MD5 hash which is not an HMAC function. The last thing missing was the generation of the salt. I struggled hard to find where this was generated but finally, I figured out it was hardcoded in the code directly.
Hardcoded salt in the code
It looks randomly generated but it is definitively not unique since all vaults created with the software would use the same salt for the key derivation. In addition, users using the same password would end up with the same decryption key. Later I discovered that the same salt value is also shared among all the vendors: SanDisk, Sony and Lexar. A less critical problem is that the number of iterations is also fixed and set to 1000. This number of iterations was good when PBKDF2 was designed but nowadays the iteration number has to be higher. For example, OWASP recommends now 310000 iterations when PBKDF2 uses HMAC-SHA-256. Nevertheless, the construction itself of the key derivation function is flawed.
The part in red does not depend on the salt or the constant. Thus it allows making precomputation attacks even if the salt is randomly generated by precomputing the part in red and XOR the result with the salt afterward. It also reduces the complexity of generating large keys since the part in red can be reused at each iteration. This shows once again that trying to implement custom Cryptography often leads to failure. This was the first problem I reported to ENCSecurity and CVE-2021-36750 was issued for this problem. ENCSecurity later patched the problem by using OpenSSL implementation of PBKDF2-SHA256 together with a randomly generated salt and 100000 iterations.
Now that I got the key derivation function, I checked how the password was verified to be correct. In fact, a file name filesystem.dat sored in the folder C:\Users\user\AppData\Local\ENCSecurityBV\ENCDataVault70\ENCDataVault contains an encrypted magic value. When the decryption of this magic value gives 0xd2c3b4a1 then the password is considered correct. The decryption algorithm used OpenSSL AES encryption. In fact for the AES-128 option, the encryption is simply AES in CTR mode with a 128-bit key generated from the key derivation function described earlier. However for the other modes the construction is more curious.
It uses multiple AES encryptions. Two for AES-256 option, four for AES-512 and eight for AES-1024. Each time AES encryption is performed with a 128-bit key. The key parts generated previously with the key derivation function are XORed to the first eight bytes of the nonce prior to the encryption and finally, all the results are XORed together. Once the password is checked to be correct eight file encryption keys are decrypted with the same algorithms. Those keys are used to encrypt and decrypt the file stored in the vaults. This is a common way to proceed since it prevents re-encrypting all the files if a user changes her password. Only the file encryption key has to be re-encrypted in this case.
I got everything I needed to implement a John the ripper plugin that allows everybody to bruteforce AES-1024 military grade encryption! The plugin is now integrated into the main repository and also includes also the bruteforce of the new key derivation function based on HMAC-PBKDF-SHA256.
The latest point I needed to elucidate was how the files themselves are encrypted. First I thought they used the same encryption algorithm based on AES. For AES-128 is still the same method, AES in CTR mode. However, I was not able to decrypt the vault using other options. I came back to Ghidra and reversed the algorithm further. It turned out that the file decryption algorithm is different.
“AES-1024″ encryption
It appears that only two iterations of AES is performed for any other option and only the last file key, for example, key[8] for AES-1024, is used and XORed with the nonce and counter. However, the construction is closed to CTR mode of operation and thus also has the malleability property. It means that if an attacker has access to the encrypted data he can make modifications that would not be detected during the decryption and the same modification is applied to the decrypted file.
In addition, the previous construction gives only a maximum security level of 256 bits since we theoretically have to bruteforce the first file key, key[1], and the last one key[8]. But we can do more, if we assume we know that two blocks that have the corresponding plaintext equal to zero we can write the following formula.
The plaintext is not involved in the equations since it is zero. Then we can decrypt each part of the equations to have:
Finally, we XOR both equations and we obtained the following result.
There is no further dependency on the last file encryption key and thus it shows a reduction to 128 bits of security. Indeed we only need to bruteforce the first file key until we obtain the right part of the equation which is known. We made the assumption that we had found two separate blocks matching the encryption of a zero block. In fact, files are encrypted in a way that includes some zero blocks. Let’s look at the encrypted file format.
Encrypted file format
The IVs are in clear followed by the file name length. Then the file name is stored encrypted followed by zero blocks until offset 0x200 where the encrypted file content starts. Thus, our previous analysis holds for this solution and shows that we have only a level of security of 128-bits for all the encryption options. Those problems were also reported to ENCSecurity and CVE-2021-36751 was attributed to that.
This analysis shows again that it is difficult to roll a custom cryptographic algorithm and also that the level of security of a solution does not depend on the number of encryptions performed.
2022
Security Advisory
May 6, 2022
BIG-IP iControl REST API Authentication Bypass
No items found.
Kudelski Security Team
This bulletin was written by Yann Lehmann of the Kudelski Security Threat Detection & Research Team
Update May 18th, 2022, 1800h UTC (2PM EDT)
According to a recent report from the U.S. Cybersecurity and Infrastructure Security Agency (CISA) and the Multi-State Information Sharing & Analysis Center (MS-ISAC) released on May 18th, exploitation of the vulnerability has been observed on both government and private sector’s network.
Several POCs of exploits have since been released to the public, making the exploitation of that vulnerability much more accessible, including to less sophisticated actors. The Cyber Fusion Center (CFC) strongly urges its clients to apply the required patches to their affected devices. If any BIG-IP’s management ports or self IPs are or were publicly exposed, the CFC recommends to consider those devices as compromised and hunt for malicious activity. CISA and MS-ISAC have provided numbers of signatures for that purpose in the “Detection Methods” of the following CyberSecurity Advisory.
Summary
iControl REST is an evolution of F5 iControl framework. Leveraging this Representational State Transfer (REST) API, an authenticated user can accomplish anything that can be accomplished from the F5 BIG-IP command line. It is an extremely powerful API.
On May 04, 2022, F5 disclosed a critical CVE, CVE-2022-1388. It may allow an unauthenticated attacker with network access to the management port or the self IP addresses of the BIG-IP system to leverage the iControl REST component. This is because some requests to iControl REST can directly bypass the authentication mechanism. Due to the capabilities of this component, anyone with network access to the management port or the self IP addresses can execute arbitrary system commands and modify services or files. From the nature of the iControl rest component, this is a control plane vulnerability that does not expose the data plane.
At the time of writing there is no publicly known exploit of that vulnerability and F5 did not disclose any details on the requests that are able to bypass the iControl REST authentication. Moreover, with a good architectural design of the BIG-IP appliances the management port and the self IP addresses should not be directly exposed without control. However, according to CFC experience, such undisclosed requests are frequently quickly reversed-engineered by security researchers and malicious actors. As such the CFC recommends mitigating the risk immediately by patching. In addition, two others less-impacting vulnerabilities, CVE-2022-26415 and CVE-2022-29474, will also be mitigated by patching.
Affected Systems
This CVE-2022-1388 impacts only the following BIG-IP versions.
If you are running a later component that the one mentioned in the fixed column above, that version should contain the fix and you are not impacted.
Solution
F5 provided fixes for the most recent branches of BIG-IP devices. The CFC recommends immediately patching your vulnerable version. If it does not exist, the CFC recommends upgrading to a newer branch.
Temporary workarounds and mitigations
Until it is possible to install a fixed version, F5 provided temporary mitigations which restrict access to iControl REST to only trusted networks or devices. As this decreases the attack surface drastically, the CFC recommends applying the described mitigation steps immediately, until the BIG-IP devices have been patched.
Those mitigation include restricting or blocking iControl REST access through management interface or the self IP addresses. Another possibility to mitigate the CVE consists in modifying the httpd configuration.
The CFC also recommends reviewing the audit logs with the BIG-IP appliance for any suspicious activity.
What the Cyber Fusion Center is doing
While there are currently no known exploits, the CFC is currently contacting all Security Device Management (SDM) clients on F5 to organize the patching of all their impacted appliances and ensure there are no traces of exploitation of this CVE.













 Threat Alert CenterLearn More About Our Detection and Response Services
Threat Alert CenterLearn More About Our Detection and Response Services










































![\mathrm{IN}[\alpha][\beta] = \{x : S(x) \oplus S(x \oplus \alpha) = \beta\}](https://cdn.prod.website-files.com/67711be5796275bf61eaabfc/685c0e00cad7775d9b999380_latex.png)