The Latest News from Research at Kudelski Security
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Audit
Crypto
Research
Network
May 23, 2023
Audit of drand Timelock Encryption
No items found.
Kudelski Security Team
The Drand team at Protocol Labs recently released a timelock encryption based on the Drand threshold network run by the League of entropy. This timelock encryption construction ensures a ciphertext will be decryptable only after some specified time has passed and not before. The cryptographic construction of the timelock encryption was recently presented in depth during the Real World Cryptography conference
Kudelski Security was engaged to audit the implementation made by Protocol Labs for timelock encryption and timelock responsible disclosure service. The security assessment considered:
tlock, the Go language implementation of the command line tool to perform timelock encryption.
tlock-js, the implementation in TypeScript of timelock encryption and age encryption.
timevault, the web interface for the time vault for encryption of vulnerability reports. A up-to-date version is running at https://timevault.drand.love/.
Part of some dependencies directly used by timelock encryption.
The audit was mainly focused on the protocol security as well as protocol specification matching the paper. During our assessment, we found:
1 High severity issue
5 Medium severity issues
3 Low severity issues
All of the issues have been corrected at the time of writing the post and the details are available in the audit report available on IPFS with CID QmWQvTdiD3fSwJgasPLppHZKP6SMvsuTUnb1vRP2xM7y4m
During our audit, we reported a bug in the Date function of the Go Language. We used the timevault tool to disclose the bug and reported in a previous post.
We thank Protocol Labs for trusting us, for their availability throughout the assessment and the nice collaboration.
2023
Security Advisory
March 30, 2023
3CX Supply Chain Attack ‘SmoothOperator’
No items found.
Kudelski Security Team
Written by Anton Jörgensson, Eric Dodge & Yann Lehmann of the Kudelski Security Threat Detection & Research Team
Updated on April 5th. We may update later on, don’t hesitate to come back.
Summary
3CX is a VoIP IPBX software development company. Their 3CX Phone System is used by more than 600,000 companies worldwide and counts more than 10 millions daily users.
3CX suffered a supply chain attack which made their 3CXDesktopApp being trojanized. This trojanized 3CXDesktopApp is the first stage of a multi-stage attack that ends in a late-stage information stealer being installed on the host. The compromised version of the app is signed by certificate used in previous version of the app.
Major EDR solution vendors are now preventing the trojanized application from running and at the time of writing no new legitimate version of the application have been provided by 3CX.
The attack is suspected by CrowdStrike’s intelligence to originate from the threat actor dubbed LABYRINTH CHOLLIMA.
Affected Application
The provider confirmed that the affected versions are :
Electron Windows app shipped in Update 7, version numbers
18.12.407
18.12.416
Electron Mac App version numbers
18.11.1213
18.12.402
18.12.407
18.12.416
Attack Overview
An analysis of the attack and indicators of compromise have already been published by CrowdStrike, SentinelOne and Sophos. According to CrowdStrike, the malicious activity includes beaconing to actor-controlled infrastructure, deployment of second-stage payloads, and, in a small number of cases, hands-on-keyboard activity.
The attack is a DLL sideloading scenario which intends to allow normal use of the 3CX desktop package without tipping victims off to suspicious activity. So far, MDR providers have identified three key components:
3CXDesktopApp.exe, the trojanized loader
d3dcompiler_47.dll, a DLL with an encrypted payload attached
ffmpeg.dll, the malicious trojan loader.
The 3CXDesktopApp is utilized as a shellcode loader with the code being run from within the heap space. That in turn leads to a DLL being loaded reflectively and called via the DLLGetClassObject export, and begins the next stage, where icon files are retrieved from Github.
The ffmpeg.dll file contains an URL from which it retrieves a malicious .ico file with an embedded Base64 payload– another download for the final stage of deployment, the infostealer. The infostealer primarily targets system and browser information from common browsers, especially the Places and History tables. Most of the domains contacted by the compromised library to download the second-stage payload (infostealer) have been taken down.
In common DLL side-loading scenarios, the malicious loader (ffmpeg.dll) would replace the clean dependency; its only function would be to queue the payload. However, in this case, this loader is fully functional, as it would normally be in the 3CX product. Instead, there is an additional payload inserted into the DllMain function.
Detection Guidance
First assess whether the compromised application is found within your environment. If that is not the case, you are not at risk for the matter of this supply chain attack.
In case you have the compromised application within your environment, please note that due to the nature of the attack, it does not mean that you are targeted. We have seen the application just being updated to the compromised version in a normal process without further action done by the threat actor behind the attack.
We recommend uninstalling the application from the hosts until a new version of the app is available. If this is not possible, to mitigate the risk we recommend containing the host in case your EDR / AV solution does not already prevents the application.
We recommend also checking for any network connections to the URL hxxps://github[.]com/IconStorages/images which was used to deliver the information stealer or even connections to raw[.]githubusercontent[.]com linked to the trojanized app.
Moreover, the references contain multiple IOCs that you can use to hunt for threats in your environment.
Finally, we recommend rotating secrets to reduce the risk of use of the captured secrets in case the infostealer was able to steal some secrets.
Temporary mitigations
The recommendation from 3CX is to still use the PWA application, but an updated version of the Electron client is now available
Contain affected assets in case your EDR/AV solution does not already prevent your compromised application and the application cannot be uninstalled.
What the Cyber Fusion Center (CFC) is doing
The CFC is currently threat hunting on every client environment to assess impact of the compromised 3CX application. If you are a CFC partner you can see the details in your partner portal under the name "[HIGH] Active Intrusion Campaign Targeting 3CX Customers"
Our Incident Response team and the CFC are in direct contact with you in case a compromised application has been observed in your environment
Our Detection Engineering team is currently pushing detection rules for your environment where applicable
Dissecting and Detecting Babuk ransomware Cryptography
No items found.
Kudelski Security Team
Written by Sylvain Pelissier and Antonio De La Piedra of the Kudelski Security Research Team
The Babuk or Babyk ransomware was detected two years ago. It’s an interesting case because after infecting the Metropolitan Police Department of Washington DC, one member of the operators decided to publish the source code of the ransomware on a forum in July 2021. However, the source code also helped other groups to create clones of the ransomware, like Rook or PrideLocker. Babuk was later copied to a GitHub repository. Studying the source code is interesting from a research point of view, and in this article, we explored the choice of Cryptography algorithms used for building this ransomware.
Even though the Babuk ransomware was released two years ago, it was still used in the wild recently on some VMware ESXi systems to encrypt VMs after having exploited OpenSLP vulnerabilities that we recently described. Babuk also spread via email phishing, unprotected RDP deployments, and unpatched vulnerabilities, particularly exploiting 3 bugs in Microsoft Exchange identified as CVE-2021-34473, CVE-2021-34523 and CVE-2021-31207.
Operation overview
The Babuk ransomware has 3 different versions, one for ESXi, one for NAS devices, and one for Windows. The Windows and ESXi version is written in pure C++ language and does not import many external libraries. It makes it very portable and is used on many different operating systems. The NAS version is written in Go language and allows binaries for ARM devices in addition to x86 devices.
The encryption algorithm consists of two steps:
The first step use asymmetric Cryptography. It means the program embeds an attacker’s public key in the encryption program but not the corresponding private key, which is left on the attacker’s machine. The usage of asymmetric key algorithms prevents the victim from recovering the attacker’s private key since it is never present on the victim’s device. First, it derives a 32-byte shared secret between the attacker public key and the file ephemeral keys using Diffie-Hellman key agreement algorithm.
The second step uses symmetric Cryptography. The shared secret is hashed to obtain a 32-byte key to be used with a stream cipher for high-speed file encryption. After file encryption, each file’s public key is written at the end of the file.
We noticed that for the ESXi version, after each operation, the sensitive information like key or algorithm states are cleared with the memset function. This prevents the typical memory forensics operations like the one we have presented in the past against GPG.
Asymmetric Cryptography
During the first step of the encryption algorithm, an ephemeral key is generated. For the ESXi version it is done by calling a function with a misleading name called csprng for each encrypted files:
voidcsprng(uint8_t* buffer, int count) {
if (FILE *fp = fopen("/dev/urandom", "r"))
{
fread(buffer, 1, count, fp);
fclose(fp);
}
}
This function consists of reading the /dev/urandom device. This can be seen as the file private key used during the Elliptic-Curve Diffie-Hellman (ECDH) algorithm. This value is stored in the variable u_priv. It is later used to generate the public key of the file stored in the variable u_publ. The attacker public key is also stored in the code in the global variable m_publ.
ECDH is typically used as a key agreement mechanism between two parties. That is, it allows generating a shared key between two parties. Then, this shared key can be used to encrypt (generally using a symmetric algorithm) messages between the two involved parties. Originally in DH, when a party a (typically Alice) and another one b, (generally Bob) want to communicate over an insecure channel do the following: they agree on using a multiplicative group of integers of order
the public part of Bob. Over the channel, each party exchanges
and
and compute the shared key
via
and
respectively, using
and
and their secret key. Similarly, DH can be performed over an elliptic curve (that is, over a multiplicative group of points on an EC) with generator
using point multiplication instead of modular exponentiation for
and
with shared key
. In this particular case of Babuk, the ECDH algorithm is implemented on the Curve25519
The ransomware reuses the code from Adam Langley for the curve implementation of Windows and ESXi versions, and it uses the implementation of the Go Cryptography package for the NAS version. This choice is smart since this curve is one of the fastest and was designed to be less prone to implementation error.
The ECDH operation over the curve25519 is performed using the curve25519-donna implementation using the following calls:
First we need to generate a private key of 32 bytes.
Given the generator of the curve and our private key, we can generate our public key as:
The first call to curve25519_donna function computes the public key of the file by doing a scalar multiplication of the file private key generated previously and the base point (or generator) of the curve, which is defined to be the standard generator on the Curve25519. The second call generates the shared secret by doing a scalar multiplication of the file private key to the attacker’s public key. The generated shared secret is typically processed using a hash function such as SHA-256.
It can be difficult to see why ECDH is used in this context. We can see the malware operator as the party Alice, which generates a shared key with the part of the code that encrypts each file. At the end of the encryption operation, the shared key of the party that performs the encryption of the files is erased and only kept by the malware operator.
The file public key is written at the end of the file to be able to decrypt it if the victim pays the ransom. Indeed the decryptor program contains the attacker’s private key. To decrypt an encrypted file, it reads the file’s public key and derives again the shared secret allowing the file decryption.
We stress that the victim which pays the ransom would receive a decryptor program and thus would be able to extract the private key of the attacker. This means that if the attacker reuses the same key for another victim, the public key in the encryptor program would match the private key already observed in a decryptor. For example, the Babuk Windows version contains a file s.txt consisting of a pair of private and public keys. We can verify with simple Python command that, indeed, the private key generates the corresponding public key.
To allow further malware research, we have released a Yara rule to identify the Curve25519 algorithm only based on the constants used. This is not obvious since Curve25519 does not use a lot of constants in its implementation, and we based our detection on the base point 9 followed by 31 zero and the constant a24 = 121665. It is a different approach from the previous Yara rule made for PrideLocker which was based on the x86 instructions.
Symmetric Cryptography
For symmetric encryption, Babuk initially uses the Chacha8 stream cipher but in the leaked source code the Sosemanuk is used in ESXi version, HC-128 is used in Windows version and Chacha20 is used in NAS version. The three of them are stream ciphers which were selected by the eSTREAM project as an efficient and secure stream ciphers. This is an interesting choice since Sosemanuk and HC-128 ciphers are not very widespread. They are pure software implementations and they are fast. Sosemanuk encrypts at 388MiB/s on my old laptop on a single core. Thus it is fast for encrypting data. It does not rely on special instructions like Intel AES-NI. Using AES in CTR mode with such instruction gives 5427MiB/s speed with OpenSSL benchmark and Salsa20 has a speed of 138MiB/s on the same benchmark. The choice of Sosemanuk or HC-128 algorithms may be because they are not well-known and lack Yara rules for detection whereas the is already existing rule for AES, Chacha and other ciphers. We have also implemented Yara rules for Sosemanuk stream cipher detection and improved the detection rule of Chacha20. Here is an example of usage of such rules combined with existing rules on a Babuk sample:
$ yara *.yar main
SHA2_BLAKE2_IVs main
Curve25519 main
Sosemanuk_constants main
Sosemanuk_encrypt_tables main
Notice that all the algorithms used in the malware are properly detected. We hope this helps researchers more quickly identify the Cryptography algorithms used in ransomware.
Conclusion
In this post, we shed some light on the cryptography used in the Babuk ransomware and explained our hypothesis on the choice of algorithms. We also released some Yara rules for detection. We hope this helps in understanding the inner working of the encryption mechanisms, and assist with further analysis of malware in the future.
2023
Audit
Crypto
TSS
Vulnerability Notification
March 23, 2023
Multiple CVEs in threshold cryptography implementations
Often MPC threshold schemes use zero-knowledge proofs to avoid participants cheating and to prove the validity of some parameters. As mentioned in RFC 8235, proofs must not be easily replayed. In the io.finnet implementation, the challenge of the Fiat-Shamir transformation (for instance, in a NIZK implementation) doesn’t include a combination of session id, context string, and a counter or random nonce thus, it allows replay attacks.
The vulnerability we identified arises from the fact that the parameter ssid for defining a session id that is typically included in the paper describing the construction is not used throughout the affected MPC implementation.
Consequently, this allows replaying and spoofing of messages under certain scenarios. In particular, the Schnorr proof of knowledge implemented does not use a session id, context or random nonce in the generation of the challenge. This could allow a malicious user or an eavesdropper to replay a valid proof sent in the past. For instance, in the NewProof function, the challenge is computed as:
We also discovered that this problem affected other zero-knowledge proofs utilized in the scheme; these proofs are identified in the paper by the following names: dec, affg, enc, logstar and mul (See Section 6 and Appendix C in the paper).
CVE-2022-47931: Collision of hash values
The functions SHA512_256 and SHA512_256i are used to hash bytes or big integer tuples, respectively. They take as input a list of values and output a hash. According to the paper, those hash functions should behave like a random oracle, and thus it should not be easy to find collisions.
The issue we found arises when hashing multiple concatenated input values, for example, a list of bytes [“a”, “b”, “c”]. The two vulnerable functions concatenate the values by adding a separator “$” between each value to obtain the string “a$b$c”. Then this string is passed to the hash function SHA-512/256 to obtain the hash result. However, the character "$" may itself be part of the input values, so this construction is prone to collisions. As an example, the two input byte array tuples ["a$", "b"] and ["a", "$b"] output the same hash value.
This test should not pass, but we obtain the following result:
=== RUN TestHashCollision
eef0de06a51453040e2fa6c7111a9e84233296f51b0992ca2a18221d232a6568
eef0de06a51453040e2fa6c7111a9e84233296f51b0992ca2a18221d232a6568
--- PASS: TestHashCollision (0.00s)
PASS
ok command-line-arguments0.003s
This issue not only invalidates the security guarantees given by the cryptographic proof of the paper (because the proof relies on the random oracle model), but it may allow practical attacks since the hash function has easy-to-find collisions. For example, the function SHA512_256i is used for the computation of a challenge in the Round 1 of the “Auxiliary Info & Key Refresh in Three Rounds”. A collision can thereby be created with some maliciously crafted parameters at this step.
CVE-2023-26556 and CVE-2023-26557: Non constant-time arithmetic is used in critical cryptographic implementations
Both issues (CVE-2023-26556 and CVE-2023-26557) are about the usage of non-constant-time operations during critical operations. Golang’s big.Int arithmetic implementation doesn’t provide constant-time methods for some arithmetic operations, which could contribute to the leaking of sensitive data. For instance, the modular Go exponentiation implementation mentions:
// Modular exponentiation of inputs of a particular size is not a cryptographically constant-time operation.
The first issue concerns the usage of Cmp, the comparison method, the Exp, modular exponentiation, and the modular inverse on sensitive values. One possible consequence is the usage of Exp could leak the value of lambda of the private key of the Paillier cryptosystem.
The second issue regarding the threshold cryptography implementation we audited is the usage of the secp256k1 curve in the Go crypto/elliptic package. This implementation does not provide a constant-time scalar multiplication method for operation on this curve as mentioned by the following comment:
// If there is a dedicated constant-time implementation for this curve operation, use that instead of the generic one.
This type of implementation could leak the involved secret scalars. An example is the computation of the public key share X which uses the secret key-share x during the second round of the scheme.
Concluding remarks
Our advice to people implementing Cryptographic protocols from academic papers, try to not deviate from the paper and try to implement time-tested solutions. The gap between an academic paper and its actual implementation can be tricky, and there are pitfalls. We hope that publishing these pitfalls and explaining them will allow for developing more secure solutions with higher resistance to attack.
2023
AI Security
Defense
Research
March 8, 2023
Addressing Risks From AI Coding Assistants Paper
No items found.
Nathan Hamiel
With all of the hype lately around AI and Large Language Models (LLMs) following the release of demos such as ChatGPT, what tends to get lost are the realities of people trying to use these tools today, not in the future. Beyond asking for recipes in the style of Shakespeare and sifting through manufactured hallucinations generated by the model, are using these tools to write and understand code.
Using these tools in coding tasks is a usage that demonstrates potential. Programming languages are more rigid in construction and less prone to interpretation than a language spoken by humans, but that doesn’t mean there aren’t plenty of risks to consider. This is why we wrote a paper detailing these risks and providing steps that security and development teams can take to address them.
In Use
Developers primarily use these tools to perform one of three tasks:
Completions
Explanations
Documentation
Each of these steps can result in issues. Most impactful are on the completions side. Developers may prompt the tool to write functions, complete lines of code, or even more advanced tasks.
Risks
There are a few risks associated with using LLMs applied to coding tasks. A couple of the highlights are listed below.
There are no guarantees of secure outputs
These tools can and do output vulnerable pieces of code. Examples of this have been shown by previous researchers as well as in this new paper. This lack of guaranteed security from the outputs means additional processes and tooling are necessary to ensure that vulnerable code doesn’t make it into production systems.
Consistency and ReliabilityIssues
How these tools make recommendations isn’t clear to the developer using the tool. Since prompts are constructed using previously written code, poor quality code written previously in the project can lead to poor quality code output from the tool. This means that even if under normal conditions the tool would have produced a secure output, the default output now becomes vulnerable.
Data leakage issues
Tools like GitHub Copilot and ChatGPT are provided in an as-a-service model. This means everything you provide to these tools via a plugin, API, or web interface is collected, possibly stored, analyzed, and reviewed by a 3rd party. It means you can lose control of your data once it’s in the hands of a 3rd party.
As an example, GitHub Copilot is basically a key logger running inside of the developer’s IDE. The following image shows GitHub Copilot performing prompt engineering based on a keypress inside the developer’s IDE, sending code, comments, and project metadata to a 3rd party.
Further Thought
These are just a few of the risks posed by these tools. For a larger analysis, more risks, as well as mitigation strategies, download the Kudelski Security Research paper Addressing Risks from AI Coding Assistants.
There’s a safe bet that more and more tools will be launched in the coming years focused on developers and using AI focused on coding tasks. Even though our paper focused mostly on GitHub Copilot and some on ChatGPT, the risks and mitigation strategies are more general and apply to these tools more generally.
2023
Blockchain
Cryptography
Research
March 6, 2023
Polynonce: A Tale of a Novel ECDSA Attack and Bitcoin Tears
No items found.
Nils Amiet
Introduction
In this blog post, we tell a tale of how we discovered a novel attack against ECDSA and how we applied it to datasets we found in the wild, including the Bitcoin and Ethereum networks. Although we didn’t recover Satoshi’s private key (we’d be throwing a party instead of writing this blog post), we could see evidence that someone had previously attacked vulnerable wallets with a different exploit and drained them. We cover our journey, findings, and the rabbit holes we explored. We also provide an academic paper with the details of the attack and open-source code implementing it, so people building software and products using ECDSA can ensure they do not have this vulnerability in their systems.
The Novel Attack
Part of the Kudelski Security Research Team’s activities includes looking into new vulnerabilities and exploits. A few months ago, while researching ECDSA nonce attacks, a member of our team discovered a more general way to exploit complex relations between nonces to retrieve the signing key. A review of existing literature seemed to confirm that this was indeed a novel insight, so we started digging into it. If you are interested in the math and details surrounding the attack, here is a link to the paper.
In a nutshell, the attack looks at the fact that you can always define a recurrence relation among nonces used in different ECDSA signatures as a polynomial of arbitrarily high degree, with unknown coefficients, modulo the order of the curve’s generator point. If you have a set of N ECDSA signatures (for the same private key) and this recurrence relation is of degree D, then (under some caveats we will talk about later) you can use the ECDSA signature equation to re-write the polynomial in terms of the private key and the recurrence unknown coefficients. We have found that the unknown coefficients can be eliminated from the polynomial, which always has the signer’s private key among its roots. So, if D is low and you have enough such correlated signatures (N ≥ D+3), then you can perform a key recovery attack by simply finding roots of a polynomial with known coefficients over a finite field, which is an easy task on a computer! To run the attack in practice, the following is required: A minimum of 4 signatures generated by the same private key, the associated public key, and the message hash associated with each signature. If the nonces obey the recurrence relation, we retrieve the private key used to generate the vulnerable signatures. The more signatures are used in the attack, the slower it gets, but the more likely it is to succeed: If you attack N signatures and their N nonces follow a recurrence relation of degree at most N-3, then you can perform a key recovery attack on ECDSA!
We tested the attack on a specially crafted set of signatures to verify that it works. You can find the proof-of-concept code here.
How Bad Is It?
In simpler words, what our attack means is that every time an ECDSA signature is generated, the signature itself gives us a relation between the nonce and the private key. If the nonces are truly randomly generated, this should never be a problem because the chance that a number of nonces picked at random fit on a low-degree polynomial recurrence relation is negligibly small.
But there is a catch: nonces are usually output by a pseudorandom number generator (PRNG) rather than being really random, and PRNGs are deterministic algorithms with relatively low complexity. In the best scenario, the PRNG used is complex enough and cryptographically secure, meaning (among other things) that any polynomial correlation between its outputs will have such an astronomically large degree that you can safely consider it indistinguishable from truly random. But weak PRNGs are basically everywhere. Take, for example, the simple case of a linear congruential generator (LCG), which is the typical textbook introduction to PRNG implementations. LCGs are to PRNG what ROT13 is to encryption and “1234” is to secure passwords. Despite that, due to their simplicity and popularity, they are the default choice for many non-critically secure applications, and it is totally possible that a “placeholder” LCG implementation slips into production code without being replaced by a more secure one.
Even more worryingly, let’s look at the recent criticism on the NIST SP 800-22 document. This publication contains in Appendix D a list of “reference random number generators” that are clearly not adequate for cryptographic purposes, including LCGs and other more or less weak generators that rely on simple quadratic or cubic recurrences and which could be affected by our attack if defined modulo the curve’s generator point order. To exploit this weakness for our attack, though, we need to have a batch of ECDSA signatures that are consecutive (meaning that the nonces are consecutive outputs from the same PRNG) and ordered (meaning that you know the order in which these signatures have been generated).
SP 800-22 also includes a list of tests that clearly fail to detect simple biases that can be demonstrated by relatively easy cryptanalysis. Because of this, NIST decided to revise this publication, but how many implementations still follow the old guidelines? And, even if the guidelines are revised, researchers have clearly shown that past and present usage of PRNGs in the wild doesn’t often follow best practices; examples include RSA keys with common factors, non-uniformly generated prime numbers and keys, small-value nonces and keys used for ECDSA in signing Bitcoin transactions, nonces with common prefixes, and others. So, summing up, we think it is reasonable to expect that our attack may affect certain implementations, but for the attack to work, we need consecutive and ordered ECDSA signatures. Where can we find a lot of these?
Bitcoin!
The Bitcoin blockchain is basically a large, public mine of ECDSA signatures. In fact, ECDSA has been used as the default signature algorithm since Bitcoin’s creation in 2009. We know that, in principle, most ECDSA signatures in the Bitcoin network are ephemeral, in the sense that the generating secret key is only used once, but we also know that this practice is not always in place, especially for the older transactions, and also Bitcoin has the advantage that the blocks follow a temporal history, which puts a certain degree of order on the signature generation time (only approximately, because there is no way to determine the order in which signatures in the same block were generated, since the timestamp is only recorded for a block, not for each signature).
The problem is that these are mainly our speculations, and we have no clue how accurate all these speculations are. So, it’s time to verify.
We downloaded and installed Bitcoin Core, the official Bitcoin client, and let it synchronize the whole chain. The sync process took about a day on a fast fiber connection, and the total blockchain size was about 430 GB, up to block 752’759 on September 5, 2022. We forked rusty-blockparser and added code to dump the ECDSA signatures and original messages that were signed for all the P2PKH transactions. There are other types of Bitcoin transactions, such as P2WPKH, but for the sake of simplicity, we only focused on these. One difficulty in dumping the required data is computing the correct original message that was signed. This message is never included in the transaction itself. Bitcoin clients are expected to re-compute the message based on bits of information stored in the chain. To be even more precise, each input in a transaction is signed, so there may be multiple signatures per transaction. To build this message, one must use information from previous transactions. To ensure we were building the message correctly, we verified all the signatures using the message we built as we were about to dump them. If a signature didn’t verify successfully, we would immediately know that something was wrong. Our source code, which builds the correct original message, is available here.
Another reason why this task is non-trivial is the lack of proper documentation about building the right message. The Bitcoin wiki contains a page with a diagram. Upon clicking this diagram, a preview is shown with a comment underneath that mentions that the diagram contains two errors! Thanks to a detailed StackExchange answer and lots of trial and error, we obtained the right message, and the signatures would validate.
Correctly dumping all the signatures and original messages from the raw blockchain data took 24 hours. The resulting output file size was 271 GB and contained 763’020’390 unique signatures. This file contained, on each line, the following information: output_address, ECDSA signature R and S values, public key, transaction ID, original message, and block timestamp. We grouped the signatures by public key and then, within each group, sorted signatures by timestamp to have more chances of picking consecutive ones. At this point, we had a dataset ready to run the attack on. But first, here are some statistics about the dataset.
These signatures were produced by private keys associated with 424’549’744 unique public keys. Of those 424 million public keys, 390 million, or about 92%, produced only 1 signature. There were 34 million public keys with at least 2 signatures, 18 million with at least 3 signatures, 12 million with at least 4 signatures, 9.6 million with at least 5 signatures, and 7.8 million with at least 6 signatures. There was a considerable number of public keys with over 200k signatures. The public key associated with the most signatures had 3.4 million signatures. This is illustrated in the chart below. Note that the y-axis uses a logarithmic scale.
The attack is generic and can be run with at least N=4 signatures (linear case) but can also be run with more signatures, for example, 5 signatures for the quadratic case and 6 signatures for the cubic case, or even more signatures. The linear case will also detect repeated nonces but is more general because it can exploit any linear recurrence relation. However, we wanted to go even further and run the quadratic case (N=5) because we thought it might give more interesting results. We considered the cost/benefit ratio of performing cubic or higher attacks to not be worthwhile, so we stopped at the quadratic case, meaning batches of 5 signatures. Since we sometimes have more than 5 signatures associated with a given public key, we decided to perform a sliding window over the signatures sorted by timestamp and run the attack on each window of size N.
So, how did it go?
We ran the sliding window attack with N=5 on a 128-core VM, and it was completed in 2 days and 19 hours. The estimated cost of the attack was about 285 USD. We broke 762 unique wallets. All of these had a zero balance. Interestingly enough, we could break all these wallets, not because of a linear or quadratic recurrence but because there was at least one repeated nonce in the signatures. So, it looks like the common mishap of ECDSA implementations using a repeated nonce was the cause of trouble.
Since we only ran the attack using a window of size 5 so far, we may have missed a few vulnerable wallets that would only have been found for public keys that had exactly 4 signatures. So, we re-ran the attack with N=4 on only the signatures from wallets with exactly 4 signatures. We were able to break 11 new wallets with a zero balance and at least one repeated nonce, thus increasing the total amount of broken wallets to 773.
We suspect (and in some cases have evidence, as we will discuss later) that all these wallets have zero balance because they have already been hacked in the past due to the repeated nonce vulnerability. We also estimated the total theoretical amount of tokens that may have been stolen from these 773 wallets to be 484 BTC, a value of approximately 31 million USD at Bitcoin’s peak.
Compromised Bitcoin Wallets And 1idiot
One question we had was, where did the money go? Who stole the tokens? To answer this question, we obtained the list of the latest transactions performed by each broken wallet address. We went through those transactions in reverse chronological order. As soon as we found a transaction that was actually sending tokens out, we assumed this was the transaction that emptied the attacked wallet. We assumed that once a wallet was cracked and tokens were stolen from it, that victim didn’t use their wallet anymore after that. This may not be completely accurate, but we think it’s a reasonable assumption. One safeguard we accounted for was to discard any transaction that happened after September 5, 2022, since this was the time until which we dumped transactions from the chain, so our dataset was already that old.
Looking at the list of destination Bitcoin addresses of broken wallets, we saw a few addresses with human-readable words, likely Bitcoin vanity addresses. For example, one address started with “1idiot”. This immediately caught our attention. Here is an excerpt from the list of destination addresses sorted by the total amount of Bitcoin that was sent there from vulnerable wallets, and an approximate USD equivalent amount, using Bitcoin’s peak rate of 65’000 USD/BTC.
RankAddress/public keyBTC receivedUSD received11HSqyCH5mF6jbRc…75.004’875’000.0021EDLS29FrUDBDUo…40.552’635’750.00314o4Miuvfed3RTW…16.981’103’700.0041Ht6dp7Kxn9htAc…4.61299’650.0051LC8y73rshNWupD…3.57232’050.00618y4Vc58sBoZMns…1.65107’250.0072103db3c3977c51…0.5334’450.0081FCpHq81nNLPkpp…0.2415’600.0091F1vpdhbxPrqAau…0.2415’600.00101GoK8AAGRcKBSk3…0.095’850.00112103bec42e5d718…0.053’250.00121idiott6U6jsgYg…0.042’600.00131my451PNkeEGfz8…0.021’300.00141CujFmDMm22pKGn…0.021’300.00151Gk94K6oxfAET2J…0.021’300.00… ………4643879zijnf1QpzVo…0.000.354651MPUBTT2jjDqDsi…0.000.35466bc1q8742wwqvxhf…0.000.21Ranking of Bitcoin addresses that received the most tokens from the vulnerable wallets we have identified at a 65’000 USD/BTC rate.
We have identified 466 different addresses or public keys the tokens that were sent to. The top address apparently received as much as 75 BTC, while the less well-ranked addresses sometimes only received a few satoshis. In total, we counted that 144 BTC (or 9.4 million USD at the above USD/BTC rate) were stolen, which is less than the total theoretical amount of 484 BTC we mentioned earlier, which sounds reasonable to us.
In the above top 15, there are 2 non-address type destinations, the ones ranked 7th and 11th. These are public keys. This means the funds were not sent to an address but to a public key (P2PK transaction type). It’s a bit more challenging to find out where the funds went for this type of transaction because we would have to index the whole chain again and see if there was a transaction that reused that output as input later. The various public bitcoin blockchain explorers we have tried did not provide that information, or it did not appear to be reliable. We didn’t go any further with tracking these public keys.
In that same list, we noticed these addresses that appeared to be vanity addresses:
Rank #12: 1idiott6U6jsgYg…
Rank #31: 1eouxuruZ7Qz64Y…
Rank #63: 1KgiftfVXuKffFZY…
Rank #93: 1dust8J4MJjfn6F…
Rank #157: 1HackfRHUGxpDAX…
Notice the appearance of words such as “idiot,” “gift,” “dust,” or “Hack” in these Bitcoin addresses. Since Bitcoin addresses are generally anonymous, unless someone can prove that they own a specific address, it is extremely difficult to determine who moved these funds without proper chain-analysis technology. Nevertheless, we investigated these addresses a bit deeper and gathered the following information.
1idiot
The address is involved in 26 transactions. Funds were sent to this address in 2017, which would seem to indicate that the money was stolen at that time. This address now has a zero balance and has sent all its funds to another vanity address called “1andreas” (1andreas3batLhQ…) on 2018-01-22. The 1andreas address has a balance of 0.036 BTC at the time of writing. Note that this address happens to be owned by Andreas Antonopoulos, who apparently received unsolicited donations of over 100 BTC in late 2017. This means that the unknown owner of the 1idiot wallet may have decided to donate the tokens they had collected from vulnerable wallets.
A total of 0.04 BTC was received by the 1idiot address from the vulnerable wallets we identified.
1eouxuru
The address is involved in 17 transactions. Funds were sent to this address in 2014. All funds were sent to the 1EDLS address, which is surprisingly ranked 2nd in the above table. The funds were then further sent to a long chain of addresses, which makes it difficult to track. We believe that this address may be involved with some cryptocurrency exchange’s address because it moved a lot of funds.
A total of 0.01 BTC was received by this address from the vulnerable wallets we identified.
1Kgift
The address is involved in only 2 transactions, which happened in 2015. It looks like the long chain of addresses formed when following this address leads to some cryptocurrency exchange (3BT57Z3DXs5Tbeaqe31EZLUbc4fDDrYGHm). This may suggest that the attacker cashed out at some point or sent the tokens further.
A total of 0.006 BTC was received by this address from the vulnerable wallets we identified.
1dust
This address is involved in a large number of transactions, 5872, to be precise. The latest transaction happened in 2015. Due to a large number of transactions, we didn’t investigate this further.
A total of 0.0039 BTC was received by this address from the vulnerable wallets we identified.
1Hack
The address is involved in 10 transactions. The first transactions happened in 2014. All funds were sent to the 1idiot address in 2017.
A total of 0.00028 BTC was received by this address from the vulnerable wallets we identified.
In addition to these vanity addresses, we also had a better look at the top 3 ranked addresses from the above table and gathered the following information.
Addresses with most received tokens from identified vulnerable wallets
The top address received 75 BTC in total. The first transaction happened in 2018. After that, some funds were regularly sent to various other addresses. Interestingly, the amount of each transaction was often 0.5 or 1 BTC. At the time of writing, this address still has a balance of 63.5 BTC, and the latest transaction happened on 2022-07-06. The addresses ranked 2nd and 3rd have received 40 BTC and 16 BTC, respectively. The address ranked 2nd appears to be linked to the 1eouxuru vanity address. Its latest transaction dates to 2014. The 3rd address’ latest transaction happened in 2015.
Public talk about these attacks
We found out that some people were openly talking about how they collected some funds from vulnerable addresses because of signatures with a repeated nonce on the bitcointalk.org forum. One example of that is this thread, where forum member “johoe” wrote on April 10, 2016, that, so far, he had collected about 7 BTC by performing a nonce reuse attack. In 2014, the same forum member participated in another thread about reused nonces. We didn’t track how many funds were openly reported to be moved using that technique on that public forum.
We wondered what the next data source to investigate would be and thought that the Ethereum blockchain would be the best candidate because of its size and popularity. That would be where we would have the greatest chances of finding vulnerable signatures in the wild.
Ethereum
Ethereum transactions are also signed with an ECDSA key. To obtain the transactions, we installed geth and lighthouse and let them synchronize. Indeed, since The Merge, it appears that two clients are necessary to obtain the whole chain: an execution client, such as geth, and a consensus client, such as lighthouse. We synchronized the chain from the genesis block up to block 15’844’545, on October 28, 2022, which is about a month after “The Merge”. The total size of the chain on disk was 1.6 TB and it took 21 days to synchronize. Also, about 120 GB of additional space was necessary for lighthouse.
We wrote a program in Python that queries our fully synchronized local geth node’s JSON-RPC API for data. We specifically use the “eth_getBlockByNumber” endpoint to obtain blocks by their number. In each block, we go through each transaction and dump the signatures and corresponding original message. The hardest part in implementing this was clearly to reconstruct the correct original message, which is not included in the transaction itself. Indeed, similarly to the Bitcoin case, Ethereum clients must recompute that message themselves to verify signatures.
In Ethereum, the format of a message to be signed changed over time, based on the number of a block. For example, in Ethereum version “Spurious Dragon” (blocks 2’675’000 to 4’369’999 included) the message is computed in a specific way. However, in Ethereum version “Berlin” (blocks 12’244’000 to 12’964’999 included), the message is computed in another way. Each version of the Ethereum protocol has its way to compute that message. Since the original message is required to verify a signature, we had to implement the construction of the message for all the 13 different Ethereum protocol versions that existed between block 0 and 15’844’545. The Ethereum yellow paper and the geth source code were of great help to build the right message for each Ethereum protocol version.
To make sure that we didn’t make any mistakes, we computed the message and checked that the signature in each transaction was valid according to that message for each transaction as we dumped the data. That way, we knew that our dataset was correct. The source code of our parser is available here.
Dumping all the signatures and messages from the start of the chain until October 28, 2022 (block 15’844’545) took 3 days and 4 hours. The output file size was 628 GB and contained 1’759’432’087 signatures. This file contained, on each line, the following information: source_address, ECDSA signature R and S values, public key, transaction ID, original message, and block time.
We grouped the signatures by public key and then, within each group, sorted the signatures by timestamp. Finally, we started running the quadratic sliding window attack (N=5) on this dataset. After about 48 hours, we had 5 successful attacks on 2 unique wallets. Both had repeated nonces, and both had a zero balance. At that point, we had processed about 22% of the input file. Since the number of successful attacks was so small and the cost of the attack was significant, we decided to stop the attack.
We couldn’t find any real-world case of recurrence nonces in the Ethereum dataset either, but we tried one more thing.
TLS
TLS is a widely used protocol to secure communications over the internet. For example, it is used in HTTPS. If a website has a TLS certificate that contains an ECDSA key, then a signature can be collected every time an initial TLS connection is established to that website.
We started by obtaining the Cisco Umbrella 1 Million domain names list. This list contains domain names ordered by the amount of traffic they receive. For the attack to work, we would need to obtain signatures that were sequentially generated using the same PRNG. To maximize the chances of this happening, we would need to be the only client establishing at least 4 TLS connections sequentially, and nobody else would need to make connections simultaneously. We thought that using domains near the bottom of that list would maximize these chances because of the lower traffic to these domains.
We wrote a program in Python that uses OpenSSL to perform a TLS handshake on each target. While the program ran, we captured the network traffic and saved it to a PCAP file. We wrote another Python program to read the PCAP file and extract the signatures and original messages. As expected, producing the correct message was a challenge. To validate that our attack was working correctly end-to-end, we set up a TLS server using a self-signed certificate for which we had previously generated the private key and used that server as a target. Then, since we had the private key, we were later able to sign the original message again but with a fixed nonce that we would reuse every time. Upon running the attack, we could successfully verify that the private key could be retrieved because of the nonce re-use. At the same time, we took the opportunity to verify the signature as we computed the message. Our code is available on Github here.
In late 2022, we ran 3 scans with different parameters. For the first scan, we used a sample of 1000 domains from some part of the list, made 10 consecutive TLS handshakes for each domain, and waited 0.2 seconds between each handshake in order not to be banned or temporarily blocked from these domains. For the second scan, we used a sample of 2000 domains from the list, performed 6 handshakes per target, and waited 0.3 seconds between each handshake. For the third and last scan, we used a sample of 10’000 domains from the list, performed 6 handshakes per target, and performed the handshakes as fast as possible.
As a result, we collected 467 unique signatures during the first scan, which took less than an hour to perform. The second scan lasted 1.5 hours, and we were able to collect 1083 unique signatures from that one. The third scan took less than a day and yielded 4505 unique signatures.
For each dataset, we sorted the signatures by public key, and then, within each group, by timestamp. Since the datasets were small, we ran the sliding window attack with N=4, 5 and 6 on a 4-core laptop. Each run was completed in a few seconds. We had zero successful attacks but only ran this on a very small sample of potential cases.
Conclusions
So, since we aren’t sipping Mojitos on a beach in some exotic location, you can tell we didn’t gain access to Satoshi’s wallet, but we recovered the private key of some Bitcoin wallets showing that the attack works. We only scratched the surface by looking at Bitcoin, Ethereum, and some TLS connections. With this initial look, we wanted to ensure that an attacker couldn’t cause financial damage before releasing the details. But there are many other locations where ECDSA is used, such as additional blockchains, batches of PGP signatures, other TLS connections, and embedded devices, just to name a few. We release this information along with code so that people and organizations can proactively ensure they are secure against these attacks and create more robust systems. We hope you find this useful.
The code for the attacks is available on Github here.
Special Thanks
Special thanks to my colleagues Marco Macchetti, for the original attack proof-of-concept and idea and Tommaso Gagliardoni for contributing to this blog post and fruitful discussions.
Let’s explain the details of the finding. The problem was found during our audit of Protocol Labs timelock encryption. tlock is the command tool providing time based encryption. It is a Go program implementing the tle command line tool providing similar features as the website timevault.drand.love. For example to encrypt a file 7 years 11 months and 1 day in the future the following command can be used:
We noticed that in the encrypted file the value after the string “tlock” is the Drand round number at which the file will be available. The current round number can be found here. Thus, the program converts the duration 7y11m1d to the round number 81988175. We found that giving a year too far in the future as an argument of tlock leads to encryption for round 1 of Drand and thus, the cleartext is immediately accessible. Here is an example of the problem:
For this example the round number has been set to 1. The problem is located in the conversion of the duration into a round number. The function parseDuration extracts the year number and subtracts it to the current date:
years, err := strconv.Atoi(pieces[0])
if err != nil {
return time.Second, fmt.Errorf("parse year duration: %w", err)
}
diff := now.AddDate(years, 0, 0).Sub(now)
return diff, nil
AddDate function is in the time package which is part of Go’s standard library providing date related functions. There is an integer overflow in the Date function called by AddDate, the year is converted to the number of days and then multiplied to the number of second in a day without any check. It leads to an erroneous negative result if the year number is too large. Here is an example of the problem: https://go.dev/play/p/Nz3aFaoA2iF. Then in tlock, the function RoundNumber, which computes the round number associated to a date, returns 1 for such negative results.
This may be a problem if the attacker can control the input date and tricks the server into encrypting something in the future whereas but the result will be accessible immediately.
The problem was reported and later corrected by Protocol Labs in the code of tlock with commit 96b5251ca25e105d241e46bcca30837fc4dcf150. An issue has been opened in Go language and a patch has been proposed but it is still present in the current version of Go (1.20) language so be careful if your program rely on the Date function for sensitive operations.
We were happy to have the opportunity to timelock encrypt and disclose our finding of a bug affecting timelock encryption itself!
2023
Security Advisory
Ransomware
February 9, 2023
Ransomware as a Service – Nevada Ransomware campaign targeting VMWare ESXi servers
No items found.
Kudelski Security Team
Written by Michal Nowakowski of the Kudelski Security Threat Detection & Research Team
UPDATE – February 14th 2023
After the first wave of ESXiArgs ransomware campaign took place on February 3rd, two main elements of the ransom have been addressed by the security community in different publications. These are malware’s initial access vector and the malware’s variations.
First publications were highlighting the exploitation of CVE-2021-21974, a heap-overflow vulnerability in ESXi’s OpenSLP service, as the malware’s initial access vector. Nevertheless, the latest reports are mentioning that not every compromised server was running the service. Therefore, it is likely that the attackers behind these campaigns may be using several known ESXi’s vulnerabilities, investigations are still on-going. And as a countermeasure to this ongoing situation, it is important to ensure that ESXi servers are up to date with VMWare’s provided patches for already know vulnerabilities. This information can be found in WMWare’s Security Advisories section: https://www.vmware.com/security/advisories/VMSA-2021-0002.html.
Compared with the first observed cases of ESXiArgs where data was sometimes recoverable, the new variant is encrypting a larger amount of data, making the recovering process advised by organizations such as CISA more challenging. An additional change is that the bitcoin wallet is not trackable anymore as the information was removed from the ransom request.
Summary
As of Friday February 3rd, 2023, VMware ESXi servers exposed to the Internet have become targets of the widespread Nevada ransomware campaign.
Nevada is a new and growing Ransomware-as-a-Service (RaaS) with an established affiliate network that invites both Russian and English-speaking entities.
Most likely, an OpenSLP vulnerability known as CVE-2021-21974 is used to perform the attack. Once the system is infected, the files are encrypted and the “.NEVADA” extension is added to their names. Additionally, a “readme.txt” ransom note is left in every directory containing encrypted files.
The ransom note explains that the attacker has stolen and encrypted the victim’s files and gives them two options: pay the ransom to maintain privacy, or risk losing precious time waiting for a miracle. The memo threatens publication of victim data on Tor if the victim does not contact the attacker within three days.
In addition, the note warns against attempting to recover files from backups as this does not mitigate the threat of publication and instructs victims not to delete or rename encrypted files or use public decryption tools, as they may contain viruses. Instead, victims are instructed to install Tor Browser and follow the provided link to reach the attackers.
The Nevada locker is written in Rust and nearly 3,000 exposed ESXi servers have already been encrypted, according to a list of Bitcoin addresses compiled by CISA advisors.
Affected Systems and/or Applications
Nevada currently targets ESXi Hypervisors from version 6.x to version 6.7. However, according to the fact that CVE-2021-21974 is used to perform the attack, the following systems may be affected as well:
Technical analysis of Nevada is ongoing. So far, the following characteristics can be confirmed:
An OpenSLP vulnerability (port 427) known as CVE-2021-21974 was used as the attack vector.
Encryption uses the public key implemented by the malware in /tmp/public.pem
The encryption process specifically affects virtual machine files of the following extensions (.vmdk, .vmx, .vmxf, .vmsd, .vmsn, .vswp, .vmss, .nvram, *.vmem)
The malware creates an argsfile to store the arguments passed to the encrypted binary file (number of MBs to be skipped, number of MBs in the encryption block, file size)
In addition to this, the following functions were noted in the RaaS partner portal. The locker is run through the console with the appropriate flags, the functions of which are described below:
Windows Version
file – encrypt selected file
rez – encrypt selected directory
sd – delete on its own after everything is finished
sc – delete background copies
left – load hidden disks
nd – find and encrypt network shares
sm – encrypt in safe mode
Linux Version
help – helpdaemon – creation and launch of a service “nevada”file – encrypt particular filedir – encrypt particular folder
esxi – disable all virtual machines
If the encryption program is run with the “-nd” flag, then it will start collecting information about network shares using the “MPR.dll” file. A recursive algorithm is implemented in the code to collect this information. Then the information about the shared directories will be stored in a queue for further encryption.
Below are the modules loaded by the encryption program:
In addition, the encryption program can display all disks, including hidden ones, if it is run with the “-lhd” argument, assigns them a corresponding letter and then the file information on any hidden disk will be written to the queue for further encryption.
If, on the other hand, the encryption program is run with the “-sm” argument, then the Windows system will be restarted and will boot into emergency mode with network functions. Directories are encrypted with “-dir” argument.
What we also know is that the ransomware is using encryption algorithm known as “Salsa20” with the constant variable “expand 32-byte k”. That is, like Petya Ransomware, it is a stream cipher, which additionally prevents access to the attacked drive.
Nevada encrypts files with “stripes” – which, combined with Salsa20, is an advantage that increases the speed of encryption. Files smaller than 524288 bytes (512KB) – will be fully encrypted, which seems to be the exception.
Interestingly, the Linux version of the Nevada locker does not encrypt files between 512KB and 1.25MB, possibly due to a bug. These files remain the same, but with an added extension .NEVADA and an additional 38 bytes at the end of the file, which may make recovery of these files possible.
At the end of the binary file, a public key and “Nevada” signature will be added.
Solution
Apply VMWare ESXi provided updates:
Since the CVE-2021-21974 vulnerability is not new, VMware recommends applying provided updates:
Block OpenSLP port 427 on internet-exposed ESXi Servers:
The CFC recommends blocking OpenSLP port 427 on ESXi servers accessible from the internet. In a situation where port 427 absolutely must be open, restrict access to trusted points of origin.
Back your data up and store it in a place inaccessible to ransomware actors.
Review and harden any security policy applicable to any internet-exposed asset.
Re-evaluate whether an asset in question must absolutely be accessible from the internet.
Apply proper monitoring for your most critical assets.
Apply the principle of least privilege: minimize users with unnecessary permissions.
Temporary Workarounds and Mitigations
Since research is ongoing and some attack vectors still need to be confirmed, it may be the case that undiscovered vulnerabilities play a role in this attack. The CFC is monitoring the situation and will update this document as events warrant.
Recovery
The U.S. Cyber Security and Infrastructure Agency (CISA) has released a script called ESXiArgs-Recover, used to recover VMware ESXi servers encrypted by the type of ransomware attack described above.
Although the script should not cause any problems, it is recommended to create backups before running the script of the recovery attempt.
To find an ESXi server’s version, please refer to your vCenter server or VMWare partner interface.
Enable Endpoint Threat Detection and Response
As described above, ransomware techniques are not novel in nature and have an increased possibility of detection by EDR technologies. If EDR is disabled or not present on ESXi servers and/or their guest VMs, enable or install it.
The CFC is preparing a threat hunt campaign which will include the regularly updated IOCs linked to the exploitation of the ESXi vulnerability, the Nevada locker, and behavioural queries crafted from internal incident response engagements for similar activity. You will be able to see the full details within your customer portal soon.
Updates
The information published in this document will be updated in accordance with ongoing research of the described vulnerability and ransomware campaign.
PBR and Kittens: A Case Involving APT 35 Presented @ CactusCon 11
No items found.
Kudelski Security Team
At the end of January 2023, James Navarro and Jacob Wellnitz from Kudelski Security’s US Incident Response team spoke at CactusCon 11 in Mesa, Arizona.
This presentation was the culmination of an almost year-long investigation and response into a cyber-attack against a client’s newly acquired subsidiary. A recording of the in-person presentation that accompanies this article can be found on YouTube. This attack is believed to have been carried out by nation state-sponsored threat actors, known as Charming Kitten and Nemesis Kitten. The Threat Actor is also known as Phosphorus, Magic Hound, Newscaster, and APT 35 among others. This Threat Actor is known to be focused on long-term, resource-intensive cyber espionage activities. MITRE provides additional information about this group on the ATT&CK project website here.
Background
Kudelski Security was contacted by an existing client after their internal security tool detected suspicious internal port scanning activity. The activity was targeting the operational technology network within an oil and gas refinery of a company they had recently acquired. The newly acquired company operates several plants, including petroleum refineries.
Kudelski Security’s client inherited all the IT infrastructure of the acquired company, including the vulnerabilities, missing patches, and compromised systems. If the acquired company had performed the SANS Security Awareness Maturity Model exercise, they would likely have fallen as a 1 on the 1 to 5 scale.
Unfortunately, the acquired company had no incident response plans or playbooks in place. The engagement, therefore, had to begin with extensive discovery.
Visit the Kudelski Security website to find out how we help clients prepare these critical documents that support incident preparedness.
Detection and Analysis
Threat Intelligence
From May 2021 onwards, the FBI and CISA released multiple advisories that specified the Tactics, Techniques, and Procedures leveraged by Advanced Persistent Threats, they attributed to Iran nexus actors, among others. While these advisories were centered on Fortinet devices and vulnerabilities, the post-exploitation activities listed were consistent with what we saw leveraged against our client. Though Fortinet devices were not used by the organization, associated IoCs in the advisories would have been useful for the organization to look for. In fact, in this instance, the IoCs would have enabled the acquired company to carry out threat hunting that would have revealed exploitation.
It was later discovered after speaking with on-site staff and over the course of the investigation by our Incident Response team that an FBI special agent had already reached out to the acquired company in April 2022 about suspicious activity specific to the organization’s domain.
Detection
The initial detection that spurred Kudelski Security Incident Response team’s engagement was an alert from Palo Alto Cortex XDR on April 18, 2022. The acquired company only noticed the alert thanks to an information technology worker logging into the Cortex console. This alert referenced potential port scanning activity related to a refinery OT network. Investigation by the Incident Response team confirmed that Cortex alerting had been disabled, likely by the threat actor, in January 2022.
2. Portion of de-obfuscated code that triggered the Cortex alert.
CrowdStrike Detections
Kudelski Security partners with CrowdStrike as our one of our preferred tools for rapid incident response services. As such, once CrowdStrike was deployed, we were able to see several detections that matched CrowdStrike’s existing Falcon Intelligence and Machine Learning models for malicious activity.
While CrowdStrike had detections that were readily available this threat actor had more tools deployed in the environment that needed to be discovered by Threat Hunting.
Analysis
The Incident Response team correlated results from threat hunting and digital forensic artifact analysis to identify compromised machines. This led to additional IoCs and more machines to investigate. Based on IoCs from the FBI, we were able to identify initial access as a Log4Shell exploitation of the network’s VMWare Horizon environment on January 8, 2022. Additional investigation showed that the threat actor stood up their command and control (C2) infrastructure on December 26, 2021. This was only a month after the discovery of Log4Shell on November 24, 2021.
Analysis of attacker activities and reverse engineering of the binaries utilized by the threat actor tracked to IoCs for a Log4Shell exploit via VMware Horizon. VMSA-2021-0028 from December 10th, 2021 shows this software as vulnerable. Forensic artifact analysis shows the attacker then compromised the VMware Identity Manager platform within the network to deploy backdoor users, escalate privileges, and enable lateral movement. Attacker outputs were then sent back via webhook.
3. Incident timeline.
Additional DotNET binaries found, and reverse engineered appeared to be of the same strain of malware used by MuddyWater. As of the time of publication only one security vendor on VirusTotal flags the C2 domain used by the malware as malicious.
Attribution
Kudelski Security Incident Response Team cyber threat intelligence correlates this attack to threat actors that, according to CISA, operate under Iranian government sponsorship. Several CISA alerts such as AA21-321A, AA22-055A, AA22-138B, AA22-174A, AA22-257A, and AA22-320A match with TTPs seen in this engagement. It should be noted that CISA’s advisory on VMWare vulnerabilities (AA22-138B) was not released until May 18, 2022, about a month after Kudelski Security Incident Response was engaged and five months after the network was exploited. There were also DotNET binaries found that match those utilized by MuddyWater, another known threat actor believed to be from the same region. This may show collaboration or shared toolsets between actors.
Compromised Systems
The Kudelski Security Incident Response team identified well over a dozen systems that were compromised by the threat actor. We define ‘compromised’ as there being evidence of malicious code executed on the system. Notable examples of systems compromised include Domain Controllers, SQL servers, Microsoft Exchange, user Virtual Desktop Infrastructure (VDI) machines, VMWare Horizon components, and the VMWare Identity Manager appliance. Many of these systems had multiple backdoor & C2 methods discovered such as ngrok tunnels, malicious webhooks, web shells, and dropped malware.
Accessed Systems
Additional systems were accessed as well. We define ‘accessed systems’ as those that show evidence of login activity by a threat actor. Several dozen systems were surreptitiously accessed such as other Domain Controllers, additional SQL servers, user VDI VMs, and file servers.
Threat Hunting
The team threat hunted across our client’s environment for many different IoCs and TTPs based on both advisories and discoveries from forensic artifact collections.
James Navarro, our Lead Threat Hunter and Detection Engineer for the US incident response team, has provided some example CrowdStrike queries that may help organizations hunt for similar activity by this threat actor.
Kill Chain in MITRE ATT&CK
TA0001 – Initial Access
The threat actor utilized the infamous Log4Shell vulnerability against the organization’s VMWare Horizon environment. Here is an example of a CrowdStrike event query that can be modified based on environment.
Log4Shell "(event_simpleName IN (""ProcessRollup2"", ""SyntheticProcessRollup2"") AND (GrandParentBaseFileName=""java*"" OR ParentBaseFileName=""java*"" OR ImageFileName=""*java*"")) OR (event_simpleName=""Network*"" AND RPort IN (""389"", ""1389"", ""636"", ""3269"", ""53"", ""5353"", ""1099"", ""11164"", ""10164"", ""2481"", ""2482"", ""1521"", ""3700"", ""6485"", ""6486"") AND NOT RemoteIP IN (""10.0.0.0/8"", ""172.16.0.0/12"", ""192.168.0.0/16"", ""127.0.0.1"")) OR (event_simpleName=""DnsRequest*"") | eval processId = coalesce(ContextProcessId_decimal,TargetProcessId_decimal,SourceProcessId_decimal,ParentProcessId_decimal) | eval temp_resolvedIps=split(IP4Records,"";"") | eval temp_cname=split(CNAMERecords,"";"") | eval temp_remoteIp=coalesce(FirstIP4Record,RemoteIP,temp_resolvedIps) | bucket _time span=30m | stats values(event_simpleName) as eventNames, values(GrandParentBaseFileName) as grandParentProcessNames, values(ParentBaseFileName) as parentProcessNames, values(ImageFileName) as processPaths, values(FileName) as processNames, values(DomainName) as domainNames, values(RemoteIP) as networkRemoteIps, values(temp_remoteIp) as coalescedRemoteIps, values(RPort) as networkRemotePorts, values(temp_cname) as dnsCNAMERecords, values(FirstIP4Record) as dnsFirstIpRecords, values(RespondingDnsServer) as dnsRespondingServers, values(CommandLine) as commandLines by processId, ComputerName, _time | convert ctime(_time) | search (grandParentProcessNames=""*java*"" OR parentProcessNames=""*java*"" OR processPaths=""*java*"") AND networkRemotePorts=""*"" | sort eventTimes desc"
TA0002 – Execution
The execution stage in this case focused on leveraging PowerShell to stage the threat actor’s malware and Command and Control infrastructure.
PowerShell Download ((CommandLine="*.DownloadString(*" OR CommandLine="*.DownloadFile(*") OR (CommandHistory="*.DownloadString(*" OR CommandHistory="*.DownloadFile(*")) | table _time ComputerName UserName FileName FilePath CommmandLine SHA256HashData
Malicious PowerShell Process - Connect To Internet With Hidden Window "TERM(""powershell"") ImageFileName=""*powershell.exe"" AND CommandLine IN (""* -Ex*"", ""*IEX*"") AND CommandLine=""*Net.WebClient*"" AND CommandLine=""*New-Object *"" AND CommandLine=""* -W*"" AND CommandLine=""* h*"" | stats min(_time) as firstTime, max(_time) as lastTime count, values(CommandLine) as commandLines by ComputerName, ImageFileName | convert ctime(*Time)"
Powershell Reverse Shell Connection (ImageFileName="*\\powershell.exe" AND (CommandLine="*new-object system.net.sockets.tcpclient*" OR CommandHistory="*new-object system.net.sockets.tcpclient*")) | table CommandLine,CommandHistory
PowerShell Pastebin Download "FileName=""powershell.exe"" CommandLine=""*http*"" CommandLine IN (""*pastebin*"", ""*github*"", ""*ghostbin*"", ""*0bin*"", ""*zerobin*"", ""*privatebin*"", ""*klgrth*"", ""*.onion*"", ""*termbin*"", ""*hatebin*"", ""*hastebin*"", ""*paste.*"", ""*dumpz*"") | stats values(_time) as eventTimes, values(ParentBaseFileName) as ParentProcesses, values(CommandLine) as commandLines count by ComputerName, ImageFileName | convert ctime(eventTimes)"
TA0003 – Persistence
Multiple persistence mechanisms were found such as reverse shells, webhooks, SSH tunnels, ngrok tunnels, BackRecover.exe, CharlesBokowski.exe, and Interop.exe.
NGROK Tunnel ((CommandLine="* tcp 139*" OR CommandLine="* tcp 445*" OR CommandLine="* tcp 3389*" OR CommandLine="* tcp 5985*" OR CommandLine="* tcp 5986*") AND (CommandLine="* start *" AND CommandLine="*--all*" AND CommandLine="*--config*" AND CommandLine="*.yml*") AND ((ImageFileName="*ngrok.exe") AND (CommandLine="* tcp *" OR CommandLine="* http *" OR CommandLine="* authtoken *")))
DNS Tunnel Technique (ImageFileName="*\\powershell.exe" AND ParentBaseFileName="*\\excel.exe" AND (CommandLine="*DataExchange.dll*" OR CommandHistory="*DataExchange.dll*"))
WebShells ImageFileName IN (aspx_okqmeibjplh.aspx,aspx_[a-z]{13}\.aspx,*\System32\Wininet.xml,dhvqx.aspx,aspx_dyukbdcxjfi.aspx) OR CommandLine In (*\Windows\Wininet.bat,*\Windows\dllhost.exe) OR FileName IN (user.exe,MicrosoftOutLookUpdater.exe,MicrosoftOutlookUpdater.bat,MicrosoftOutlookUpdater.xml,GoogleChangeManagement.xml,Connector3.exe)
Backdoors, WebShell, BackRecover.exe, CharlesBokowski.exe, Interop.exe event_simpleName IN ("ProcessRollUp2","SyntheticProcessRollUp2","DnsRequest","DomainName") FileName IN (ECB64Power.exe, impact.zip, CharlesBokowski.zip, CharlesBokowski.exe, Interop.exe, BackRecover.exe, HpDriverUpdate.exe, Details-of-Complaint.docx, Arabic.dotm, Taliban%20relations.docx, NY.docx) OR CommandLine IN (C:\CharlesBokowski.exe, get-displayname interop) OR SHA256HashData IN ("7cb14b58f35a4e3e13903d3237c28bb386d5a56fea88cda16ce01cbf0e5ad8e", "Ea127fbcbc184d751cc225e2e87149708ed93df1f37a526d06d0e48b92d48a7e", "3418b564f18ca0f4f162945fca2922d3d20e669b0242017701e59708c5fce582", "3355c82f26acff64860005ba137c267bb07c426ac3a4ac4dd6fe1cab50ab36e2a", "8a286eb052bb77061d9e947b5d3f41f1ee469ace8cf7437a890b2365992b2ac0", "c40923c35aed9830a3c295894663cb8bfd331640f5593f0d4da729accb22c4bb", "7f680efadef8c0b3a192b2814077b7b5d8543d20dd24b1d8939f3fec013059a3", "b5cbce4831a0fd36c728a5c3408a341df41f2d58f618a70b47cac13c7b351ff4", "83cb42558f9bbaea5a19240d06149cf4994c94bc3a64485d6f11bd23e6e05fb1", "a913a35858f873ba7169a2a335d7efa185f186366d7b10fa325fc39d233b9b7f ", "a8c062846411d3fb8ceb0b2fe34389c4910a4887cd39552d30e6a03a02f4cc78", "28DE2CCFF30A4F198670B66B6F9A0CE5F5F9B7F889C2F5E6A4E365DEA1C89D53", "01CA3F6DC5DA4B98915DD8D6C19289DCB21B0691DF1BB320650C3EB0DB3F214C", "7CC5E44FD84D98942C45799F367DB78ADC36A5424B7F8D9319346F945F64A72") | table _time,ComputerName,FileName,UserName, CommandLine, SHA256HashData
TA0004 – Privilege Escalation
Harvesting credentials, Dumped LSASS, Password Guessing/Cracking. This threat actor harvested credentials, dumped LSASS and utilized password attacks. Forensic artifact collection analysis showed that tools used included BloodHound, SharpHound, and MimiKatz.
BloodHound and SharpHound Hack Tool ((ImageFileName="*\\Bloodhound.exe*" OR ImageFileName="*\\SharpHound.exe*") OR ((CommandLine="* -CollectionMethod All *" OR CommandLine="*.exe -c All -d *" OR CommandLine="*Invoke-Bloodhound*" OR CommandLine="*Get-BloodHoundData*") OR (CommandHistory="* -CollectionMethod All *" OR CommandHistory="*.exe -c All -d *" OR CommandHistory="*Invoke-Bloodhound*" OR CommandHistory="*Get-BloodHoundData*")) OR ((CommandLine="* -JsonFolder *" OR CommandHistory="* -JsonFolder *") AND (CommandLine="* -ZipFileName *" OR CommandHistory="* -ZipFileName *")) OR ((CommandLine="* DCOnly *" OR CommandHistory="* DCOnly *") AND (CommandLine="* --NoSaveCache *" OR CommandHistory="* --NoSaveCache *"))) || table _time ComputerName UserName ImageFileName CommandLine CommandHistory ShaHashData256
Mimikatz "ImageFileName IN (""sekurlsa::logonpasswords"", ""lsadump::dcsync"", ""lsadump::backupkeys + dpapi::chrome"", ""misc::memssp"") OR TargetFileName IN ("*mimilsa.log", "*.kirbi") OR TemporaryFileName IN (“mimilsa.log”, "*.kirbi") | stats values(_time) as eventTimes, values(ImageFileName) as processPaths, values(ParentBaseFileName) as parentProcessNames, values(CommandLine) as commandLines count by ComputerName | convert ctime(eventTimes)"""
LSASS Process Memory Dump Files (((TargetFileName="*\\lsass.dmp" OR TargetFileName="*\\lsass.zip" OR TargetFileName="*\\lsass.rar" OR TargetFileName="*\\Temp\\dumpert.dmp" OR TargetFileName="*\\Andrew.dmp" OR TargetFileName="*\\Coredump.dmp") OR (TemporaryFileName="*\\lsass.dmp" OR TemporaryFileName="*\\lsass.zip" OR TemporaryFileName="*\\lsass.rar" OR TemporaryFileName="*\\Temp\\dumpert.dmp" OR TemporaryFileName="*\\Andrew.dmp" OR TemporaryFileName="*\\Coredump.dmp")) OR ((TargetFileName="*\\lsass_2*" OR TargetFileName="*\\lsassdump*" OR TargetFileName="*\\lsassdmp*") OR (TemporaryFileName="*\\lsass_2*" OR TemporaryFileName="*\\lsassdump*" OR TemporaryFileName="*\\lsassdmp*")) OR (((TargetFileName="*\\lsass*") OR (TemporaryFileName="*\\lsass*")) AND ((TargetFileName="*.dmp*") OR (TemporaryFileName="*.dmp*"))) OR ((TargetFileName="*SQLDmpr*" OR TemporaryFileName="*SQLDmpr*") AND (TargetFileName="*.mdmp" OR TemporaryFileName="*.mdmp")) OR ((TargetFileName="nanodump*" OR TemporaryFileName="nanodump*") AND (TargetFileName="*.dmp" OR TemporaryFileName="*.dmp")))
Password Cracking with Hashcat (ImageFileName="*\\hashcat.exe" OR ((CommandLine="*-a *" OR CommandHistory="*-a *") AND (CommandLine="*-m 1000 *" OR CommandHistory="*-m 1000 *") AND (CommandLine="*-r *" OR CommandHistory="*-r *")))
Hydra Password Guessing Hack Tool (((CommandLine="*-u *" OR CommandHistory="*-u *") AND (CommandLine="*-p *" OR CommandHistory="*-p *")) AND ((CommandLine="*^USER^*" OR CommandLine="*^PASS^*") OR (CommandHistory="*^USER^*" OR CommandHistory="*^PASS^*")))
CrackMapExec Command Execution (((CommandLine="*cmd.exe /Q /c * 1> \\\\*\\*\\* 2>&1" OR CommandLine="*cmd.exe /C * > \\\\*\\*\\* 2>&1" OR CommandLine="*cmd.exe /C * > *\\Temp\\* 2>&1") OR (CommandHistory="*cmd.exe /Q /c * 1> \\\\*\\*\\* 2>&1" OR CommandHistory="*cmd.exe /C * > \\\\*\\*\\* 2>&1" OR CommandHistory="*cmd.exe /C * > *\\Temp\\* 2>&1")) AND ((CommandLine="*powershell.exe -exec bypass -noni -nop -w 1 -C \"*" OR CommandLine="*powershell.exe -noni -nop -w 1 -enc *") OR (CommandHistory="*powershell.exe -exec bypass -noni -nop -w 1 -C \"*" OR CommandHistory="*powershell.exe -noni -nop -w 1 -enc *"))) | table CommandLine,CommandHistory
RomCom RAT & Privilege Escalation Tool ((((ParentBaseFileName="*\\cmd.exe") AND ((CommandLine="*ApcHelper.sys*" OR CommandLine="*/c*" OR CommandLine="*del*" OR CommandLine="*system*" OR CommandLine="*sc*" OR CommandLine="*create*" OR CommandLine="*ApcHelper*" OR CommandLine="*kernal*") OR (CommandHistory="*ApcHelper.sys*" OR CommandHistory="*/c*" OR CommandHistory="*del*" OR CommandHistory="*system*" OR CommandHistory="*sc*" OR CommandHistory="*create*" OR CommandHistory="*ApcHelper*" OR CommandHistory="*kernal*"))) OR (ImageFileName="*\\powershell.exe" AND ((CommandLine="*Invoke-WebRequest*") OR (CommandHistory="*Invoke-WebRequest*")))) OR (ImageFileName="*\\cmd.exe" AND (CommandLine="*rundll32.exe*" OR CommandHistory="*rundll32.exe*") AND (CommandLine="*startWorker*" OR CommandHistory="*startWorker*") AND (CommandLine="*comDll.dll*" OR CommandHistory="*comDll.dll*") AND (CommandLine="*system32*" OR CommandHistory="*system32*")))
TA0005 – Defense Evasion
The threat actor targeting our client utilized various methods to avoid defensive measures within the network. These tactics included obfuscating PowerShell script names, using Base64 encoding, using valid account credentials, and abusing Domain Admin accounts. There was also detected usage of Impacket, LOLBins, and, perhaps the most interesting finding, disablement of the Palo Alto Cortex EDR’s alerting.
Impacket Tool Execution ((ImageFileName="*\\goldenPac*" OR ImageFileName="*\\karmaSMB*" OR ImageFileName="*\\kintercept*" OR ImageFileName="*\\ntlmrelayx*" OR ImageFileName="*\\rpcdump*" OR ImageFileName="*\\samrdump*" OR ImageFileName="*\\secretsdump*" OR ImageFileName="*\\smbexec*" OR ImageFileName="*\\smbrelayx*" OR ImageFileName="*\\wmiexec*" OR ImageFileName="*\\wmipersist*") OR (ImageFileName="*\\atexec_windows.exe" OR ImageFileName="*\\dcomexec_windows.exe" OR ImageFileName="*\\dpapi_windows.exe" OR ImageFileName="*\\findDelegation_windows.exe" OR ImageFileName="*\\GetADUsers_windows.exe" OR ImageFileName="*\\GetNPUsers_windows.exe" OR ImageFileName="*\\getPac_windows.exe" OR ImageFileName="*\\getST_windows.exe" OR ImageFileName="*\\getTGT_windows.exe" OR ImageFileName="*\\GetUserSPNs_windows.exe" OR ImageFileName="*\\ifmap_windows.exe" OR ImageFileName="*\\mimikatz_windows.exe" OR ImageFileName="*\\netview_windows.exe" OR ImageFileName="*\\nmapAnswerMachine_windows.exe" OR ImageFileName="*\\opdump_windows.exe" OR ImageFileName="*\\psexec_windows.exe" OR ImageFileName="*\\rdp_check_windows.exe" OR ImageFileName="*\\sambaPipe_windows.exe" OR ImageFileName="*\\smbclient_windows.exe" OR ImageFileName="*\\smbserver_windows.exe" OR ImageFileName="*\\sniffer_windows.exe" OR ImageFileName="*\\sniff_windows.exe" OR ImageFileName="*\\split_windows.exe" OR ImageFileName="*\\ticketer_windows.exe"))
Metasploit / Impacket PsExec Service Installation "event_simpleName=*Service* | regex ServiceImagePath=""^.*\\\\[a-zA-Z]{8}\.exe($|\"".*)"" | regex ServiceDisplayName=""^([a-zA-Z]{4}|[a-zA-Z]{8}|[a-zA-Z]{16})$"" | stats values(_time) as Occurrences, values(ServiceDisplayName) as serviceNames, values(ServiceImagePath) as servicePaths count by ComputerName, event_simpleName | convert ctime(Occurrences)"
Defense Evasion Techniques of SystemBC Malware ((ImageFileName="*\\reg.exe") AND (((CommandLine="*HKLM\\Software\\Policies\\Microsoft\\Windows Defender*" OR CommandHistory="*HKLM\\Software\\Policies\\Microsoft\\Windows Defender*") AND (CommandLine="*add*" OR CommandHistory="*add*") AND (CommandLine="*Disable*" OR CommandHistory="*Disable*") AND (CommandLine="*/d 1 /f*" OR CommandHistory="*/d 1 /f*")) OR ((CommandLine="*DisableBlockAtFirstSeen /t REG_DWORD /d 1 /f*" OR CommandLine="*SpynetReporting /t REG_DWORD /d 0 /f*" OR CommandLine="*SubmitSamplesConsent /t REG_DWORD /d 2 /f*") OR (CommandHistory="*DisableBlockAtFirstSeen /t REG_DWORD /d 1 /f*" OR CommandHistory="*SpynetReporting /t REG_DWORD /d 0 /f*" OR CommandHistory="*SubmitSamplesConsent /t REG_DWORD /d 2 /f*"))))
Wevtutil Cleared Log "ImageFileName=""*\\wevtutil.exe"" CommandLine IN (""* cl *"", ""* sl *"", ""*set-log*"", ""*clear-log*"") | stats values(_time) as eventTimes, values(ImageFileName) as processPaths, values(ParentBaseFileName) as parentProcessNames, values(CommandLine) as commandLines count by ComputerName | convert ctime(eventTimes)" WMIC Uninstall Security Product (((CommandLine="*wmic*" OR CommandHistory="*wmic*") AND (CommandLine="*product where *" OR CommandHistory="*product where *") AND (CommandLine="*call uninstall*" OR CommandHistory="*call uninstall*") AND (CommandLine="*/nointeractive*" OR CommandHistory="*/nointeractive*")) AND ((CommandLine="* name=*" OR CommandLine="*caption like *") OR (CommandHistory="* name=*" OR CommandHistory="*caption like *")) AND ((CommandLine="*Antivirus*" OR CommandLine="*AVG *" OR CommandLine="*Crowdstrike Sensor*" OR CommandLine="*DLP Endpoint*" OR CommandLine="*Endpoint Detection*" OR CommandLine="*Endpoint Protection*" OR CommandLine="*Endpoint Security*" OR CommandLine="*Endpoint Sensor*" OR CommandLine="*ESET File Security*" OR CommandLine="*Malwarebytes*" OR CommandLine="*McAfee Agent*" OR CommandLine="*Microsoft Security Client*" OR CommandLine="*Threat Protection*" OR CommandLine="*VirusScan*" OR CommandLine="*Webroot SecureAnywhere*" OR CommandLine="*Windows Defender*" OR CommandLine="*CarbonBlack*" OR CommandLine="*Carbon Black*" OR CommandLine="*Cb Defense Sensor 64-bit*" OR CommandLine="*Dell Threat Defense*" OR CommandLine="*Cylance *" OR CommandLine="*LogRhythm System Monitor Service*") OR (CommandHistory="*Antivirus*" OR CommandHistory="*AVG *" OR CommandHistory="*Crowdstrike Sensor*" OR CommandHistory="*DLP Endpoint*" OR CommandHistory="*Endpoint Detection*" OR CommandHistory="*Endpoint Protection*" OR CommandHistory="*Endpoint Security*" OR CommandHistory="*Endpoint Sensor*" OR CommandHistory="*ESET File Security*" OR CommandHistory="*Malwarebytes*" OR CommandHistory="*McAfee Agent*" OR CommandHistory="*Microsoft Security Client*" OR CommandHistory="*Threat Protection*" OR CommandHistory="*VirusScan*" OR CommandHistory="*Webroot SecureAnywhere*" OR CommandHistory="*Windows Defender*" OR CommandHistory="*CarbonBlack*" OR CommandHistory="*Carbon Black*" OR CommandHistory="*Cb Defense Sensor 64-bit*" OR CommandHistory="*Dell Threat Defense*" OR CommandHistory="*Cylance *" OR CommandHistory="*LogRhythm System Monitor Service*")))
TA0006 – Credential Access
This threat actor used valid credentials that were harvested through various means, Mimikatz to crack password hashes, and tools such as KrbRelayUp to elevate their access.
KrbRelayUp Hack Tool event_simpleName="win" AND (Image="*\\KrbRelayUp.exe" OR OriginalFilename="KrbRelayUp.exe" OR (CommandLine="* relay *" AND CommandLine="* -Domain *" AND CommandLine="* -ComputerName *") OR (CommandLine="* krbscm *" AND CommandLine="* -sc *") OR (CommandLine="* spawn *" AND CommandLine="* -d *" AND CommandLine="* -cn *" AND CommandLine="* -cp *"))
ADCSPwn Hack Tool ((CommandLine="* --adcs *" OR CommandHistory="* --adcs *") AND (CommandLine="* --port *" OR CommandHistory="* --port *"))
Findstr GPP Passwords (ImageFileName="*\\findstr.exe" AND (CommandLine="*cpassword*" OR CommandHistory="*cpassword*") AND (CommandLine="*\\sysvol\\*" OR CommandHistory="*\\sysvol\\*") AND (CommandLine="*.xml*" OR CommandHistory="*.xml*"))
VeeamBackup Database Credentials Dump (ImageFileName="*\\sqlcmd.exe" AND (CommandLine="*SELECT*" OR CommandHistory="*SELECT*") AND (CommandLine="*TOP*" OR CommandHistory="*TOP*") AND (CommandLine="*[VeeamBackup].[dbo].[Credentials]*" OR CommandHistory="*[VeeamBackup].[dbo].[Credentials]*"))
TA0007 – Discovery
As with most Windows environment attacks, this threat actor used various tools built into the Windows operating system (such as netsh) to map out the domain structure.
Enable Network Discovery - Netsh.exe "(ImageFileName=""*netsh.exe"" CommandLine=""*advfirewall*"" CommandLine=""*set*"" CommandLine=""*rule*"" CommandLine=""*enable=Yes*"" CommandLine=""*Network Discovery*"") | stats values(ParentBaseFileName) as ParentBaseFileName, values(CommandLine) as CommandLine BY ImageFileName, ComputerName"
WMIC Discovery process=~"*wmic*" AND (cmdline=~"*path*" or cmdline=~"*get*" or cmdline=~"*list*")
Suspicious Process Patterns NTDS.DIT ((((ImageFileName="*\\NTDSDump.exe" OR ImageFileName="*\\NTDSDumpEx.exe") OR (((CommandHistory="*ntds.dit*") OR (CommandLine="*ntds.dit*")) AND ((CommandHistory="*system.hiv*") OR (CommandLine="*system.hiv*"))) OR (CommandHistory="*NTDSgrab.ps1*" OR CommandLine="*NTDSgrab.ps1*")) OR (((CommandHistory="*ac i ntds*") OR (CommandLine="*ac i ntds*")) AND ((CommandHistory="*create full*") OR (CommandLine="*create full*"))) OR (((CommandHistory="*/c copy *") OR (CommandLine="*/c copy *")) AND ((CommandHistory="*\\windows\\ntds\\ntds.dit*") OR (CommandLine="*\\windows\\ntds\\ntds.dit*"))) OR (((CommandHistory="*activate instance ntds*") OR (CommandLine="*activate instance ntds*")) AND ((CommandHistory="*create full*") OR (CommandLine="*create full*"))) OR (((CommandHistory="*powershell*") OR (CommandLine="*powershell*")) AND ((CommandHistory="*ntds.dit*") OR (CommandLine="*ntds.dit*")))) OR ((CommandHistory="*ntds.dit*" OR CommandLine="*ntds.dit*") AND ((ParentBaseFileName="*\\apache*" OR ParentBaseFileName="*\\tomcat*" OR ParentBaseFileName="*\\AppData\\*" OR ParentBaseFileName="*\\Temp\\*" OR ParentBaseFileName="*\\Public\\*" OR ParentBaseFileName="*\\PerfLogs\\*") OR (ImageFileName="*\\apache*" OR ImageFileName="*\\tomcat*" OR ImageFileName="*\\AppData\\*" OR ImageFileName="*\\Temp\\*" OR ImageFileName="*\\Public\\*" OR ImageFileName="*\\PerfLogs\\*"))))
TA0008 – Lateral Movement
SMB shares were accessed, SSH abused, and of course RDP exploited.
SMB Share Server Access by Admin event_simpleName=SmbServerShareShareOpenedEtw UserName=Administrator | table _time ComputerName UserName FileName CommandLine
RDP Hijacking traces "event_simpleName=""RegSystemConfigValueUpdate"" AND RegObjectName=""*\RDP-Tcp"" AND RegValueName=""PortNumber"" | rename RegNumericValue_decimal as ""NewRDPPort"" | table timestamp, ComputerName, NewRDPPort"
SSH outside USA "event_platform=lin event_simpleName=CriticalEnvironmentVariableChanged, EnvironmentVariableName IN (SSH_CONNECTION, USER) | eventstats list(EnvironmentVariableName) as EnvironmentVariableName,list(EnvironmentVariableValue) as EnvironmentVariableValue by aid, ContextProcessId_decimal | eval tempData=mvzip(EnvironmentVariableName,EnvironmentVariableValue,"":"") | rex field=tempData ""SSH_CONNECTION\:((?<clientIP>\d+\.\d+\.\d+\.\d+)\s+(?<rPort>\d+)\s+(?<serverIP>\d+\.\d+\.\d+\.\d+)\s+(?<lPort>\d+))"" | rex field=tempData ""USER\:(?<userName>.*)"" | where isnotnull(clientIP) | iplocation clientIP | lookup local=true aid_master aid OUTPUT Version as osVersion, Country as sshServerCountry | fillnull City, Country, Region value=""-"" | table _time aid ComputerName sshServerCountry osVersion serverIP lPort userName clientIP rPort City Region Country | where isnotnull(userName) | sort +ComputerName, +_time | search NOT Country IN (""-"", ""United States"")"
Remote Desktop Protocol (RDP) port manipulation "(RegObjectName=""*Terminal Server\\WinStations\\RDP-Tcp*"" OR CommandLine=""*Terminal Server\\WinStations\\RDP-Tcp*"") | rex field=CommandLine ""(?i).*[d|value] (?<cmd_value>\\d.*?)( |\""|'|$)"" | eval rdpPort=coalesce(RegNumericValue_decimal,cmd_value) | rename ComputerName as hostname | stats values(UserName) as username values(_time) as occurrences values(rdpPort) as rdpPort values(ImageFileName) as initiatingProcess count by hostname | convert ctime(occurrences)"
RDP Reverse Tunnel "RPort=3389 AND (RemoteAddressIP6=""::1"" OR RemoteAddressIP6=""0:0:0:0:0:0:0:1"" OR RemoteAddressIP4=""127.*"") | stats values(_time) as Occurrences, values(RemoteAddressIP4) count by LocalAddressIP4 | convert ctime(Occurrences)"
TA0009 – Collection
Once the threat actor had achieved access to much of the network, they got to work stealing information from many places. Browser profiles and credentials were stolen, Windows credentials were gathered, and data was written to archives for exfiltration.
SQLite Chromium Profile Data DB Access ((Product="SQLite" OR (ImageFileName="*\\sqlite.exe" OR ImageFileName="*\\sqlite3.exe")) AND ((CommandLine="*\\User Data\\*" OR CommandLine="*\\Opera Software\\*" OR CommandLine="*\\ChromiumViewer\\*") OR (CommandHistory="*\\User Data\\*" OR CommandHistory="*\\Opera Software\\*" OR CommandHistory="*\\ChromiumViewer\\*")) AND ((CommandLine="*Login Data*" OR CommandLine="*Cookies*" OR CommandLine="*Web Data*" OR CommandLine="*History*" OR CommandLine="*Bookmarks*") OR (CommandHistory="*Login Data*" OR CommandHistory="*Cookies*" OR CommandHistory="*Web Data*" OR CommandHistory="*History*" OR CommandHistory="*Bookmarks*")))
SQLite Firefox Profile Data DB Access ((Product="SQLite" OR (ImageFileName="*\\sqlite.exe" OR ImageFileName="*\\sqlite3.exe")) AND ((CommandLine="*cookies.sqlite*" OR CommandLine="*places.sqlite*") OR (CommandHistory="*cookies.sqlite*" OR CommandHistory="*places.sqlite*"))) Powershell ChromeLoader Browser Hijacker (ImageFileName="*\\chrome.exe" AND (ParentBaseFileName="*\\powershell.exe" OR ParentBaseFileName="*\\pwsh.exe") AND ((CommandLine="*--load-extension=*") OR (CommandHistory="*--load-extension=*")) AND ((CommandLine="*\\AppData\\Local\\*") OR (CommandHistory="*\\AppData\\Local\\*")))
Suspicious Infostealer Malware ((ImageFileName="*\\powershell.exe*") AND (CommandLine="*Start*" OR CommandHistory="*Start*") AND (CommandLine="*-Sleep*" OR CommandHistory="*-Sleep*") AND (CommandLine="*-s10*" OR CommandHistory="*-s10*") AND (CommandLine="*Remove*" OR CommandHistory="*Remove*") AND (CommandLine="*-Item*" OR CommandHistory="*-Item*") AND (CommandLine="*-Path*" OR CommandHistory="*-Path*") AND (CommandLine="*\\Setupfinal.exe*" OR CommandHistory="*\\Setupfinal.exe*") AND (CommandLine="*-Force*" OR CommandHistory="*-Force*"))
Browser Credential Store Access (((FileName="*\\AppData\\Local\\Google\\Chrome\\User Data\\Default\\Network\\Cookies*" OR FileName="*\\Appdata\\Local\\Chrome\\User Data\\Default\\Login Data*" OR FileName="*\\AppData\\Local\\Google\\Chrome\\User Data\\Local State*") OR (FileName="*\\Appdata\\Local\\Microsoft\\Windows\\WebCache\\WebCacheV01.dat" OR FileName="*\\cookies.sqlite" OR FileName="*release\\key3.db" OR FileName="*release\\key4.db" OR FileName="*release\\logins.json")) AND NOT ((Image="*\\firefox.exe" OR Image="*\\chrome.exe") OR (Image="C:\\Program Files\\*" OR Image="C:\\Program Files (x86)\\*" OR Image="C:\\WINDOWS\\system32\\*") OR (Image="*\\MsMpEng.exe" OR Image="*\\MpCopyAccelerator.exe" OR Image="*\\thor64.exe" OR Image="*\\thor.exe") OR ParentImage="C:\\Windows\\System32\\msiexec.exe" OR (Image="System" AND ParentImage="Idle")))
TA0010 – Exfiltration
Once the data the threat actor was interested in was gathered, it was stored in zip archives and transported out of the network via multiple methods and the tunnels that had been established.
WinSCP Session Created - Possible Data Exfil "TERM(""console"") AND CommandLine IN (""*sftp://*"" ""*scp://*"" ""*ftps://*"") | stats values(_time) as eventTimes, values(GrandParentBaseFileName) as grandParentProcessNames, values(ParentBaseFileName) as ParentProcesses, values(CommandLine) as commandLines, values(ContextProcessId_decimal) as contextProcessDecimal count by ComputerName, ImageFileName | convert ctime(eventTimes)"
Potential Data Staging or Exfiltration - Common Rclone Arguments "TERM(""copy"") (CommandLine=""*copy*"" CommandLine=""*transfers*"" CommandLine=""*multi-thread-streams*"" CommandLine=""*-q*"" CommandLine=""*ignore-existing*"" CommandLine=""*auto-confirm*"") | rename CommandLine as commandLine ImageFileName as process RawProcessId_decimal as processID ParentBaseFileName as parentProcess ParentProcessId_decimal as parentProcessID ComputerName as hostname | stats list(_time) as occurrences list(commandLine) as commandLine list(process) as process list(processID) as processID list(parentProcess) as parentProcess list(parentProcessID) as parentProcessID by hostname | convert ctime(occurrences)"
Reverse Tunnel FileName="Frps.exe" OR CommandLine="https://github.com/fatedier/frp/releases/download/v0.33.0/frp_0.33.0_windows_amd64.zip" OR FileName=SynchronizeTimeZone.xml ImageFileName IN (start.vbs,nvContainerRecovery.bat)
Exfiltration Domains DomainName IN (filemail.com,ufile.io,mega.nz,easyupload.io)
Compress Data and Lock With Password for Exfiltration With 7-ZIP (((CommandLine="*7z.exe*" OR CommandLine="*7za.exe*") OR (CommandHistory="*7z.exe*" OR CommandHistory="*7za.exe*")) AND (CommandLine="* -p*" OR CommandHistory="* -p*") AND ((CommandLine="* a *" OR CommandLine="* u *") OR (CommandHistory="* a *" OR CommandHistory="* u *"))) | table CommandLine,CommandHistory
TA0011 – Command and Control
Besides the usual Command and Control interfaces over tunnels that are seen frequently, the incident response team was able to find evidence that the threat actor leveraged two Twitter profiles for additional C2 activity. As of the time of publication one of these accounts has been suspended and the other is dormant. Kudelski Security will not be releasing the account information at this time to allow for further research.
Ngrok Tunnel ((CommandLine="* tcp 139*" OR CommandLine="* tcp 445*" OR CommandLine="* tcp 3389*" OR CommandLine="* tcp 5985*" OR CommandLine="* tcp 5986*") AND (CommandLine="* start *" AND CommandLine="*--all*" AND CommandLine="*--config*" AND CommandLine="*.yml*") AND ((ImageFileName="*ngrok.exe") AND (CommandLine="* tcp *" OR CommandLine="* http *" OR CommandLine="* authtoken *")))
When possible, the Incident Response team leveraged CrowdStrike’s network containment feature to deny the adversary continued access to systems. This feature allowed us to perform analysis on the machine while simultaneously preventing network access from the system to other systems on the network. We then performed forensic artifact collection and were able to surgically remove persistence mechanisms and malicious binaries. While normally, backups would be leveraged to restore systems to a known good state, this was not possible due to the extended dwell time of the threat actor. Additionally, backups are not always healthy and sometimes will not restore properly if they have not been properly maintained.
Actions Taken
Kudelski Security has many different options to deal with an incident. Choices will always depend on the level of access provided by the client. These options include:
Process termination on detection of Indicators of Attack
Block malicious behaviors based on activity on endpoints.
Process termination upon detections of IoCs.
Block process execution based on custom rulesets developed from gathered forensic artifact collections.
Remediation of persistence mechanisms
Removal of known malware off disk
Removal of Scheduled Tasks or Cron jobs
Termination of known malicious processes in memory
Network Detection Rules
Blocks put in place for various protocols such as SSH at the host and network level.
Blocks entered into firewall rulesets for known malicious IPs
Stoppage of outbound SMB traffic to the Internet
Recovery
Patching
The Incident Response team performed several actions to assist with post breach remediation after this incident. The most important actions taken centered on vulnerability management. In one site alone we closed over 370,000 vulnerabilities. The record for one week of patching at a single site was over 100,000 vulnerabilities closed.
Purple Teaming
To identify additional vulnerabilities that needed remediation, we used a Purple Team approach. This provided information that would supplement reporting from various other tools such as CrowdStrike or Tenable Nessus scanners. Red Team operators were brought in to perform external and internal penetration testing and delivered their findings from across the organization to the remediation team.
Notable findings include:
Open camera access.
An open mail relay exposed to the Internet that allowed spoofing any email address in the domain.
Access to operational technology control and monitoring surfaces via unauthenticated VNC.
Critical vulnerabilities in appliances.
Post Incident Activities
Reporting and Lessons Learned
We generated a report for this incident that totaled over 600 pages and covered all known compromised and accessed devices. Every incident response client receives a report and a post-incident ‘Lessons Learned’ meeting where we explain the contents of the report.
MDR Onboarding
Many Kudelski Security clients choose to roll the existing work they have performed deploying EDR into our Managed Detection and Response services. In this case the client already utilized MDR through us and had the advantage of our assistance in bringing the subsidiary under management.
Continuous Vulnerability Scanning
We partner with Tenable to provide continuous vulnerability scanning as services through the Cyber Fusion Center (CFC), our MDR SOC.
Ongoing Threat Hunting
We performed additional threat hunts in not only the onboarded environment, but also across the client’s existing MDR footprint as part of this engagement. This means that the client not only got to leverage individualized threat hunts for the network in question but gained additional value for the parent company.
Benefits of MDR – Economies of Scale
After the engagement we ensured our detection engineering teams and the CFC teams at Kudelski Security got all the relevant intelligence, so that our entire client base could benefit. This work ultimately rolls up into our Threat Navigator tool, which is a MITRE ATT&CK visualization software designed to allow clients to find their detection gaps, prioritize gap elimination, and systematically strengthen their resilience to the threats that are targeting their organization.
4. Example of a MITRE ATT&CK tactic in Threat Navigator.
The Kudelski Security US Incident Response team would like to thank CactusCon 11 for allowing us to present this case to the international cybersecurity community present at the conference. The recorded presentation can be found on YouTube. We would also encourage anyone reading this article to consider Kudelski Security for their Incident Response needs. We are happy to discuss how we can provide ongoing and immediate coverage via an incident response retainer.
This article was written by Jacob Wellnitz with intense collaboration by James Navarro, both members of the Incident Response team that worked this case.
You don’t know what you don’t know – a compromise assessment will help you find out for sure if there is a threat active in your environment.
2023
Blockchain
Crypto
January 12, 2023
Mitigating Risk in the Allbridge Core
No items found.
Kudelski Security Team
A blockchain bridge enables interoperability between two different blockchains. Typically, it allows one to transfer data and tokens from one chain to another. More accurately, the tokens are locked-up on one chain, and some other tokens are released from a pool or minted on another. With proper accounting of tokens, the user may interact with tokens on the target blockchain as if they had been transferred from the original blockchain.
Bridges also have unique features that can make maintaining security difficult. They involve different blockchains with novel implementations, architectures, and programming languages. Considering the relatively large amount of funds that are often locked up in bridges, security is particularly important. There are several recent examples of zero-day exploits specifically targeting bridges with catastrophic consequences.
The best practice for beginning to mitigate the risk of these bridges and minimize the ability of attackers to cause harm is by performing regular security assessments and architecture reviews of the contracts and code to identify and remediate known and potential vulnerabilities. There is a focused methodology that we follow in reviewing security vulnerabilities in such a system. Not only do we perform a threat assessment of possible exploits of the system, but we also perform a code review, analyze fund loss scenarios, and assess program authentication scenarios for each identified component that participates in the token movement activities.
Allbridge Core is a cross-chain bridge for stablecoins with liquidity pool staking and rewards. It enables cross-chain transfers between EVM and non-EVM chains, using messaging protocols to perform swaps. For a more in-depth overview of Allbridge and its roadmap, please see Allbridge’s Core documentation page here.
Allbridge engaged Kudelski Security to perform a security assessment of their Allbridge Core (bridge) to identify and mitigate any unexpected risks associated with their smart contract bridge. This work was completed in December of 2022. During our review, we analyzed and reviewed the pool contract as this contains functionality to withdraw tokens and contains token swap mechanics. This is because the following points are known vulnerable areas of a pool contract:
Access control of any token withdrawal
Functions that use the exchange curve
Logic of the token swap
Accounting of virtual tokens
Numerical errors in accounting
Our assessment focused on code committed as of October 7th, 2022, and focused on the following objectives:
Help the client to better understand its security posture on the external perimeter and identify risks in its deployed chain & contract infrastructure.
Provide a professional opinion on the maturity, adequacy, and efficiency of the security measures that are in place.
Identify potential issues, including loss of funds scenarios, and include improvement recommendations based on the result of our tests.
The first step was a workshop with Allbridge where their team walked us through their repository, covering design and functionality. We then created a threat model outlining the architecture of their bridge and the areas of risk based on that architecture. Next, we conducted an in-depth code review where we identified and classified vulnerabilities focusing on both the smart contracts and the underlying math they were based on. We discussed those with the Allbridge team as they were found and provided recommendations to remediate them.
Throughout the assessment, the Allbridge team was highly collaborative and responsive to any questions or comments that we had. Their code was well-structured and thoughtful. It was a pleasure working with the Allbridge team and we are looking forward to working with them again in the future.
Recently, the timelock encryption tool timevault.drand.love was released by the Drand team at Protocol Labs. This tool allows encrypting data which will be decipherable by everyone at a certain date and not before.
The tool is based on the Drand project. Basically Drand outputs a beacon every 30 seconds. This beacon is a verifiable source of public entropy. It means it can be used by a lottery, a casino or in a game to select a winner and everybody can verify that this value was generated randomly in a fair way. The beacon is generated by a group called the League of Entropy. It is composed of companies and universities and Kudelski Security runs one of the League of Entropy nodes. As long as the majority in the group behaves honestly, the source of public entropy can be trusted.
However, the beacon happened to also be a threshold signature from the League of Entropy. Thus, it allowed the building of a timelock encryption system where the League of Entropy is seen as the trusted third party. The public key used to lock the data is the round number when the data will be accessible, and the private key is the signature issued only at the specific round number.
Timelock encryption allows several interesting applications. One of them is timelock responsible disclosure. When a security researcher find a bug, usually, she contacts the vendor to report the bug and depending on the nature of the bug, an embargo time is decided before the bug is publicly revealed. It leaves time for the vendor to patch the problem without leaving the users at risk. With timelock encryption, the vulnerability report is locked until a certain date, and after this date, the report is decipherable by everyone, and nobody can prevent the release of the report, not even the author.
We think this is an interesting tool for security researchers, and we took the opportunity to try this tool to lock a vulnerability report which has been communicated to the vendor, and it will be publicly accessible the 23 February 2023 at 00:00 (CEST) .
2023
Security Advisory
December 22, 2022
Linux Kernel ksmbd Remote Code Execution Vulnerability
No items found.
Kudelski Security Team
Note: This bulletin was written by Eric Dodge of the Kudelski Security Threat Detection & Research Team
Summary
The Zero Day Initiative (ZDI) recently disclosed the existence of a critical severity vulnerability discovered in newer versions of the Linux Kernel, specifically with the implementation of Kernel space implementation of SMB (ksmbd). The flaw exists within how the kernel handles the processing of certain SMB2 commands.
It is important to note that this vulnerability only applies to those systems with ksmbd enabled and that have SMB exposed to the network. Additionally, the vulnerability was introduced with Linux Kernel version 5.15 (released in November of 2021) and the KSMBD module is considered experimental and not enabled by default.
It is unlikely that ksmbd is used broadly by organizations as most deployments that require SMB support are likely running Samba instead.
The Cyber Fusion Center strongly encourages organizations who have enabled Kernel Space SMB support via ksmbd to apply patches as soon as possible.
Affected Systems
This vulnerability impacts Linux systems running Kernel 5.15 that also have the Kernel space implementation of SMB (ksmbd) enabled, which was introduced with the Linux Kernel 5.15.
Technical Details (limited at this time)
Successful exploitation of this vulnerability does not require authentication, and to date only requires that ksmbd is enabled on the host. Ksmbd was introduced with Linux 5.15. Proper exploitation of SMB2_TREE_DISCONNECT commands will allow a remote attacker to execute arbitrary code on the impacted systems and enable them to leak memory (Similar to the heartbleed vulnerability).
The vulnerability stems from the lack of validation of the existence of an object, prior to performing operations on the object. Using this an attacker can leverage the vulnerability to then execute code that is in the context of the kernel.
Solution / Workarounds
The current recommendation is to patch all impacted systems to the 5.15.61 kernel version.As this is a fairly new version of the Linux Kernel, please consult your Operating System’s Maintainer to understand how this vulnerability is being addressed
What the Cyber Fusion Center is doing
The CFC will continue to keep up to date with this vulnerability to provide further updates as they become available.













 Threat Alert CenterLearn More About Our Detection and Response Services
Threat Alert CenterLearn More About Our Detection and Response Services



































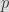
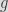



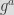
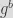
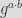
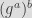
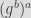
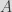
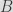
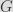

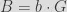


{kind=link}