






Much has been made about the privacy and confidentiality issues with ChatGPT. Just take a look at the press for a list of companies prohibiting ChatGPT usage by their employees, but I’d argue there’s an equally if not far more concerning issue impacting privacy and confidentiality beyond ChatGPT, and that’s individual experimenters distributed across organizations.
There’s a fair bet that people inside your organization are experimenting with LLMs, and they may not be the people you expect. These aren’t developers, they are the everyday staff spread across your organization. Focusing prohibitions and policies on ChatGPT can be a distraction from the more significant issue, far more data can leave your organization over API calls than through the web interface of ChatGPT, and it’s happening right now without your knowledge.
Accessibility and Ease of Use
Back in the day, security teams struggled with cloud computing because anyone with a credit card could have a cloud. Security professionals would claim they weren’t using cloud resources, but when you talked with developers, they said they used cloud resources all of the time. This disconnect has come to the AI space because anyone with a credit card has access to a hosted large language model.
To take this a step further, there’s no need to have a GPU or even know anything about machine learning to leverage this technology. Anyone capable of writing sentences and copying/pasting some Python code can make API calls to a hosted LLM. API calls are simple to understand, here’s the page on OpenAI’s website for the ChatCompletion API. Not to mention the countless tutorials on YouTube (both good and bad.)
Below I’ve put an entire working example that if placed into a Jupyter notebook, would print the answer to the question, “What was the first production vehicle made by Ford Motor Company?”
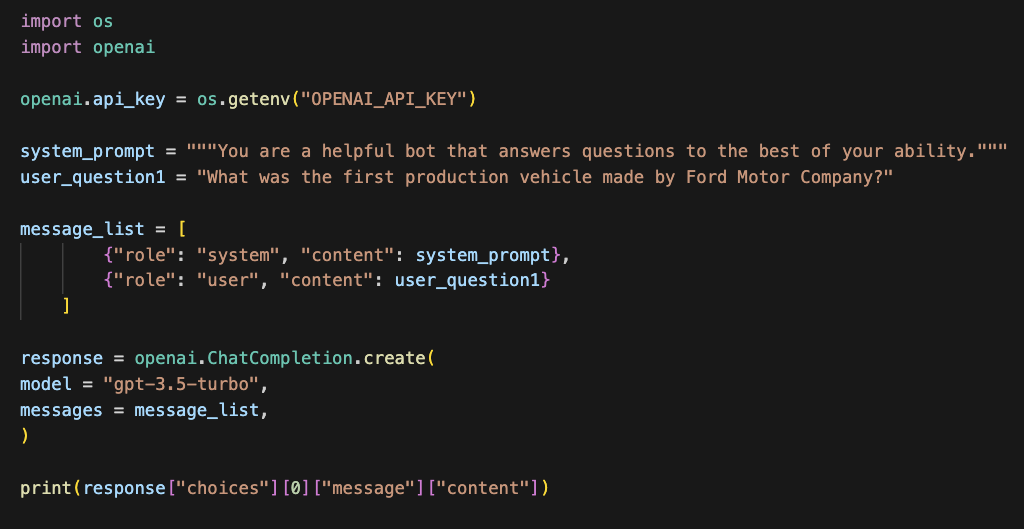
This accessibility means that it may not be your developers experimenting with LLMs to optimize tasks and solve problems, it could be anyone at your company (and probably is). Regardless of what industry you are in, this affects you.
It’s also important to realize that it’s not just OpenAI you need to think about. Many different providers, from startups to big tech companies, have stood up solutions in this area and are hosting access to LLMs, all with different business models and usage and privacy policies.
People experimenting may not have clear goals or even know what they expect in return. Quite often, they may feed data into an LLM to merely see what happens or, due to hype, expect some kind of magic to happen. Regardless, the impact on organizations is the same.
Negative Impacts
The positive impacts of successful experiments should be obvious, and I won’t highlight them here. There are several real-world negative impacts that result from these activities. I’ll highlight a couple below.
Privacy and Confidentiality
Privacy and confidentiality are the obvious impacts that everyone talks about. Your sensitive business data could leave your organization and end up in the hands of a 3rd party. This data could then be used and viewed by humans to train and improve future models. Even if you trust the 3rd party, you are still at the mercy of their data storage and data protection requirements.
Keep in mind data stored for training and improvement of models isn’t stored with the same requirements as it would be in your regular cloud computing account. It needs to be optimized and available for retraining as well as human evaluation.
Violation of Regulatory Requirements
The various staff at your organization may not be familiar with all of the regulatory requirements your organization falls under. Given this, it could be possible that staff uses the simple applications they build to violate regulatory requirements. Think about taking something like patient data and using an LLM to summarize the content or a simple application they build to make a sensitive decision about coverage.
Inexperience With Development
People outside of your development team aren’t accustomed to following development standards and associated security guidelines. As such, they may make critical mistakes in their code. For example, they may grab data from the Internet and through it into a Python eval() or, even worse, a fully autonomous experiment that spins away trying to optimize a task that also grabs untrusted data and throws it into an eval().
This is less of a concern than an application being exposed externally because, as an experiment, it shouldn’t be deployed or exposed more widely, but depending on what the code does and the permissions of the user running it, it can still have negative consequences that affect the company.
Inexperience With Evaluation
Staff members outside your development teams may not be familiar with how to evaluate and benchmark the software that they build. The system could be giving the right answer but for the wrong reasons or give the wrong answer entirely, but since it’s coming from an AI, it’s more trusted. This could lead to a business impact where incorrect decisions are made because of a faulty design. There are many cases were an LLM is the wrong solution to a problem, but it may be chosen anyway because of ease of use or hype around the technology.
Sunken Cost-Driven Adoption
It may be the case that since people spent time building something, they use it anyway, regardless of how effective it is or whether it actually optimizes a process. Anyone who’s ever worked at a company where this has happened has felt this pain. These are experiments and not formal development projects. As such, proper requirements haven’t been gathered, and critical pieces are often missed that are necessary for generalizing to a larger team or problem.
I’ve had this happen multiple times in my career, where someone hacks together a partially functional, almost non-usable experiment and tries to drive the adoption of it to a larger group, selling it as the new way to do things. Don’t do this to your coworkers.
Addressing The Problem
The first thing to realize is that this isn’t just a problem for the developers inside your organization. It’s a larger problem that potentially affects everyone in your organization. Think about approaching the issue with a larger scope more like how you do awareness for and issue like phishing. Give people and overview of the issue and a solution.
Avoid Strict Prohibitions
It’s tempting, in this case, to just give a blanket “No” and move on with life. This would be a mistake for many reasons, but mostly for the fact that this approach doesn’t work. This is one of the lessons we should have learned by now. Just like the cloud, people will do what they are going to do and just won’t tell the security team. Instead of saying no, you should be harnessing people’s excitement and pointing them in the right direction. There’s a much better chance for conversation when the people engaging you feel like they won’t get a no in response.
Guidelines and Policy
Create some clear guidelines and policy choices around usage and ensure they are communicated to the entire company. An entire list of items that should go in here is specific to each company and industry, as well as outside the scope of this blog post.
Any prohibitions for certain types of data or use in specific processes should be clearly outlined along with an associated “why.” Many times, if people understand the why they are much more likely to follow the policy.
If you have an approved provider for LLM services, make sure it’s specified, and any process you have internally for communicating and approving experiments should also be documented.
By the way, now would be a good time to work on that data classification project that you’ve been putting off for the past decade. This will help in ensuring specific data is protected from exposure.
Workshops and Awareness Activities
Set up a series of workshops for discussions and encourage people to reach out. Use these activities to communicate the guidelines and policies and give people a path to share and explore their ideas in a productive way. Highlight what could go wrong and how to avoid it. Communicate specific processes you put in place around how people can reach out and what they need to do to experiment.
Experiment Inventory and Registry
It’s good to keep a running list of these experiments at your organization, so you can follow up if necessary. It would be best to have a process where people can register an experiment on their own and mark it as decommissioned when completed. Without adding too much overhead, you’ll want to capture, at a minimum, who owns the experiment, what business process it supports, what data it uses, and the experiment’s status.
This is good for collaboration, but from a security perspective, there are some high-level things you want to be sure of.
- Sensitive data isn’t leaving the company
- Regulatory and Policy Requirements are being followed
- Fully autonomous experiments are kept in check
- The impact of a security issue is kept to a minimum
I realize this can be an ask, and a lot can go wrong here, but it’s a start. It’s better than not knowing. Perform some experiments yourself around this topic and see what works best for your organization.
Feedback
This will be a new process at your organization. Ensure feedback is flowing in both directions. Collect feedback on the process to ensure that issues are being addressed. Ensure that feedback is also flowing back to the participants of the process, where they may be opening up unnecessary risk.
Conclusion
Due to the hype and accessibility, there is a whole lot of sensitive data leaving organizations without their knowledge. With the right approach, you can put a series of steps in place to ensure you maintain an innovative spirit while ensuring your data is protected. With the right balance you can leverage a productivity boost while also ensuring your data is protected.
If you are concerned about attacks such as prompt injection, have a look at our previous blog about reducing the impact of prompt injection through application design.



